Оптимизация обработки запросов
Фактор селективности в случае нескольких предикатов
Когда несколько предикатов используются для выборки строк из одной таблицы, оптимизатор следует некоторым фиксированным правилам, которые комбинируют фактор селективности каждого из них в некоторый суммарный. Первое правило не зависит от того, как много предикатов рассматривается, когда вычисляется итоговый фактор селективности для предикатов, содержащих операторы равенства и неравенства. Это следующие правила.
Использование оптимизатора для оптимизации выполнения запросов
Существует много вариантов увеличения производительности запросов. Основной идеей для выбора самого подходящего является построение запроса таким образом, чтобы оптимизатор запросов СУБД вычислил оптимальные по стоимости пути доступа для его выполнения.
С другой стороны, первоначальный набор индексов может не удовлетворять требованиям по производительности для всех запросов. Например, некоторые запросы, содержащие колонки соединения, не являющиеся ни первичным, ни внешним ключами, могут выполняться медленно. Для таких запросов, чтобы они удовлетворяли критериям производительности, необходимо добавить дополнительные индексы. Однако нецелесообразно создавать один или более индексов для каждого оператора выборки, поскольку:
Следовательно, общая цель проектирования состоит в том, чтобы создать набор индексов, который отвечает требованиям производительности для всех транзакций к базе данных. Это и есть оптимальный набор индексов.
Подсказка является частью комментария, следующего за ключевым словом команды, и отмечается символом «+».
Для эффективного переписывания плана выполнения запроса необходимо в течение некоторого времени накопить знания о работе СУБД с базой данных, в частности, определить список проблемных запросов и их характеристик. При решении задач оптимизации проблемных запросов нужно следовать следующим рекомендациям:
В качестве режима может быть задано одно из следующих значений:
| Подсказка | Описание |
|---|---|
| ROWID | Использование идентификатора |
| CLUSTER | Сканирование ключа кластера |
| HASH | Сканирование хэш-индекса |
| INDEX | Сканирование индекса |
| INDEX_ASC | Сканирование индекса в порядке возрастания |
| INDEX_DECS | Сканирование индекса в порядке убывания |
| AND_FFS | Быстрое полное сканирование индекса |
| AND_EQUAL | Использование нескольких индексов со слиянием результатов |
| FULL | Полное сканирование таблицы |
Более подробно об использовании оптимизатора запросов СУБД Oracle можно прочитать в рекомендованной к лекции литературе.
Процедура пересчета селективности индексов
Если размер таблицы оптимизатор всегда определяет более-менее актуально, то селективность индексов не пересчитывается автоматически. В результате оптимизатор будет оценивать селективность, которая далека от реальности. Так что, селективность нужно пересчитывать самостоятельно.
Пересчет селективности индексов происходит при их создании, при alter index active, и при set statistics index indexname.
Например, вы создали таблицу, создали индексы, а затем наполнили таблицу данными. У всех индексов этой таблицы селективность так и будет равна 0, пока вы не пересчитаете селективность.
Или, вы создали таблицу, индексы, заполнили данными, сделали бэкап-рестор (при ресторе индексы создаются заново, и селективность будет актуальной). А потом в некоторых таблицах поменяли 30-40% данных (добавили, удалили, или изменили). И селективность тоже будет неактуальной.
(дело в том, что в системных таблицах 0 и null равнозначны по смыслу, поэтому приходится писать coalesce)
Однажды, рассматривая содержимое дистрибутива InterBase 2020, я обнаружил интересный файл ris.sql, который поставляется в комплекте с версии XE3.
В ris.sql находится процедура для пересчета индексов, которая использует execute statement для set statistics, и позволяет выборочно обновлять статистику для разных типов индексов. Оказалось, что эта процедура прекрасно работает на Firebird, без изменений.
Вот текст этой процедуры:
(убрана часть комментария, аналогичная описанию выше, остальные комментарии перевел)
/*
* Copyright (C) 2011-2015 Embarcadero Technologies, Inc
* All Rights Reserved.
После вызова процедуры нужно сделать COMMIT.
*** Ограничения ***
— Для выполнения процедуры над всеми индексами БД вы должны быть
владельцем БД или SYSDBA
— скрипт будет работать только на тех версиях, которые поддерживают EXECUTE STATEMENT
*/
CREATE EXCEPTION CIS_INVALID ‘Invalid argument to Stored Procedure COMPUTE_INDEX_SELECTIVITY’;
/* Пересчет селективности для всех индексов в БД */
IF (index_range = 0) THEN BEGIN
FOR SELECT RDB$RELATION_NAME, RDB$INDEX_NAME
FROM RDB$INDICES
WHERE COALESCE (RDB$SYSTEM_FLAG, 0) = 0
ORDER BY RDB$RELATION_NAME, RDB$INDEX_NAME
INTO :table_name, :index_name
DO
BEGIN
ddl_string = ‘SET STATISTICS INDEX ‘ || :index_name;
EXECUTE STATEMENT ddl_string;
END
EXIT;
END
/* Пересчет селективности всех индексов таблицы */
IF (index_range = 1) THEN BEGIN
FOR SELECT RDB$RELATION_NAME, RDB$INDEX_NAME
FROM RDB$INDICES
WHERE RDB$RELATION_NAME = :entity_name
ORDER BY RDB$RELATION_NAME, RDB$INDEX_NAME
INTO :table_name, :index_name
DO
BEGIN
ddl_string = ‘SET STATISTICS INDEX ‘ || :index_name;
EXECUTE STATEMENT ddl_string;
END
EXIT;
END
/* Пересчет селективности конкретного индекса */
IF (index_range = 2) THEN BEGIN
ddl_string = ‘SET STATISTICS INDEX ‘ || :entity_name || ‘ ‘;
EXECUTE STATEMENT ddl_string;
EXIT;
END
/* Пересчет селективности всех системных индексов БД,
за исключением индексов по RDB$ENCRYPTIONS. Закомментировано для Firebird, т.к. в нём такой таблицы нет
*/
IF (index_range = 3) THEN BEGIN
FOR SELECT RDB$RELATION_NAME, RDB$INDEX_NAME
FROM RDB$INDICES
WHERE RDB$SYSTEM_FLAG=1
— AND RDB$RELATION_NAME NOT IN (‘RDB$ENCRYPTIONS’)
ORDER BY RDB$RELATION_NAME, RDB$INDEX_NAME
INTO :table_name, :index_name
DO
BEGIN
ddl_string = ‘SET STATISTICS INDEX ‘ || :index_name;
EXECUTE STATEMENT ddl_string;
END
EXIT;
END
END ;
Собственно, для Firebird здесь можно было ничего не менять, всё работает. Я разве что закомментировал условие на RDB$ENCRYPTIONS, такой таблицы в Firebird нет. Но можно было и не комментировать, т.к. это условие всегда выдаст True.
Примеры вызова процедуры (из того же ris.sql):
Табличная селективность или селективность строк – соотношение количества строк, возвращаемых запросом к общему количеству строк в таблице.
Таким образом, чтобы рассчитать селективность индекса довольно посмотреть значение DISTINCT_KEYS в динамическом представлении ALL_INDEXES. Селективность чаще вычисляют в процентах. Чем больше этот процент, тем меньше (хуже) селективность. Селективность хороша, если мало строк имеют одинаковые ключевые значения.
Индексный доступ к данным имеет смысл при хорошей селективности. Это утверждение верно при равномерном распределении данных. Однако для ситуации с неравномерным распределением данных такой подход не оправдан. Рассмотрим пример. Предположим у нас есть только два ключевых значения: 1 и 2. Только у одной записи нашей таблицы ключевое поле равно 2. Все остальные записи имеют ключевое поле равное 1. Для нашего случая distinct_key=2, а значит селективность 0,5! Но реально для доступа по предикату ключ=2 использование индекса вполне оправдано. А для предиката ключ=1 индексный доступ вообще не имеет смысла.
Читайте также
Как регламентировать перекуры в течение рабочего дня? Можно ли разрешать опаздывать к началу рабочего дня? Можно ли чатится во время…
Вам нравится, когда у маркетинга и продаж развязаны руки? Когда они жгут по полной и продажи прут? Когда целевая аудитория…
У каждого из нас в жизни наступает такой момент, когда мы говорим себе, всё, хватит, надоел мне босс, надоел этот…
SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Индексы: когда селективность столбца не является обязательным требованием
Недавно я столкнулся с одним из устоявшихся убеждений, что первый столбец индекса должен быть высоко селективным, т.е. он должен указывать на одну или незначительное число строк. Это не всегда так, и я покажу вам почему.
В прошлом я неоднократно говорил, что при определении индекса первый столбец должен быть высоко селективным. Я подкреплял это утверждение примером, что «пол» не является в этом смысле хорошим полем данных, т.к. оно не селективно. Данные здесь содержат либо М (мужчина), либо Ж (женщина). Однако давайте рассмотрим очень простой случай, когда пол в первом столбце определения индекса может улучшить производительность запроса.
В аттаче находится скрипт (установка и тестовые примеры), который иллюстрирует, что может произойти при наличии и отсутствии покрывающего индекса, а также каким образом переопределение покрывающего индекса может изменить производительность запроса. Строки 19-41 создают таблицу dbo.Customer в базе TempDB и заполняют её данными из базы данных AdventureWorks2017.
При таким образом определенной таблице рассмотрим следующий запрос (строки 97-106). Я также включаю вывод фактического плана запроса (Ctrl-M):
Возвращается 359 строк. Полная стоимость плана 0,171855 при 217 логических чтениях и сканировании кластеризованного индекса. План запроса выглядит так:
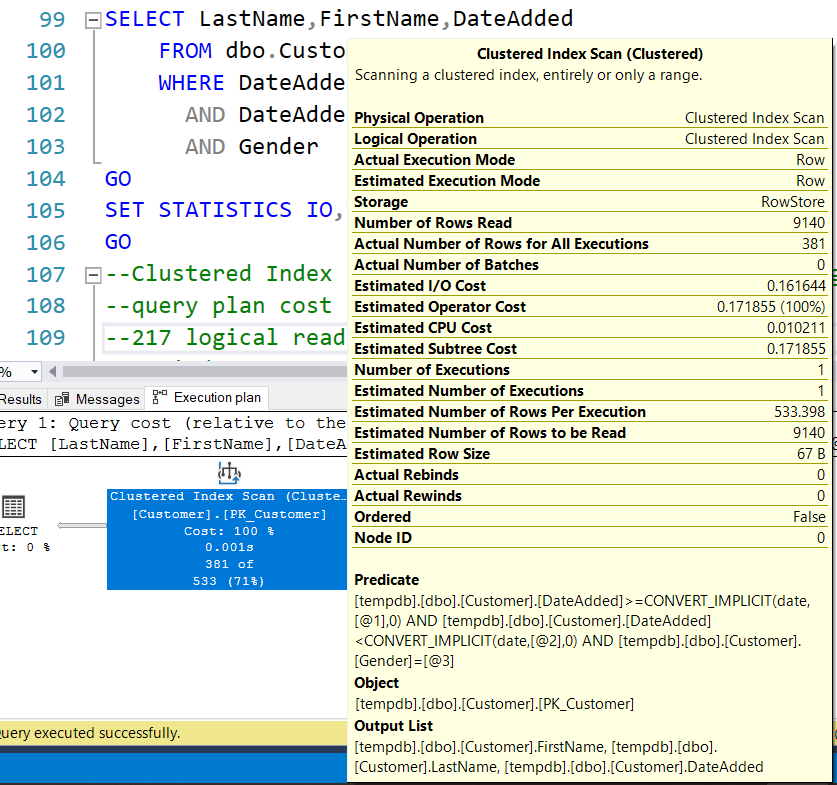
Обратите внимание, что оператор запроса имеет только предикат, выполняющий фильтрацию по DateAdded и Gender. Никаких индексов рекомендовано не было.
Однако, рассматривая запрос, мы можем добавить покрывающий индекс, о чем говорилось выше. Заметьте, что я выбрал первым столбцом столбец даты (т.к. он более селективный, чем столбец Gender).
Теперь, если снова выполнить тот же запрос, мы получим тот же результат, но стоимость запроса составит 0,005594 при 6 логических чтениях и поиске в некластеризованном индексе. План запроса теперь выглядит так:
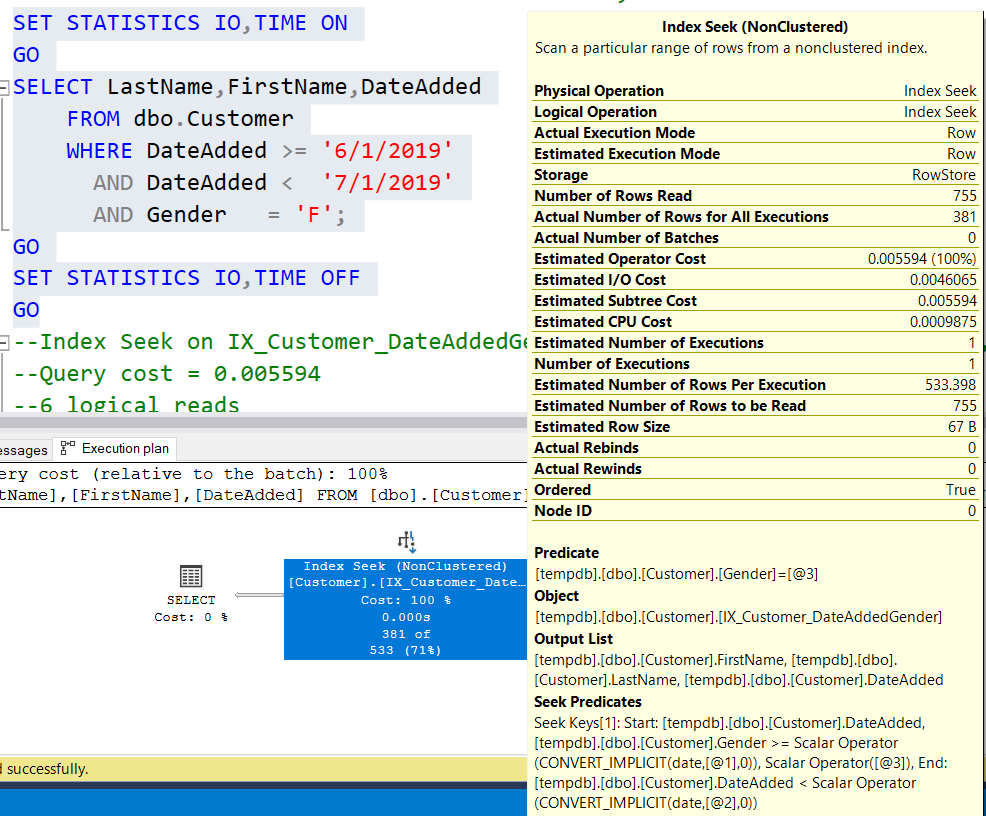
Теперь мы имеем поисковый предикат (Seek Predicate) на DateAdded и фильтрующий предикат на DelFlag при серьезном улучшении стоимости запроса (и меньшем числе логических чтений).
Но мы знаем, что оптимизатор может извлечь преимущество от поиска строк в возрастающем или убывающем порядке. Давайте переопределим покрывающий индекс, как показано ниже:
Перезапустив исходный запрос с этим новым индексом, мы получим стоимость запроса 0,0053502 (немного ниже по сравнению с предыдущим запросом), 4 логических чтения и новый поиск в некластеризованном индексе. Если мы посмотрим план запроса:
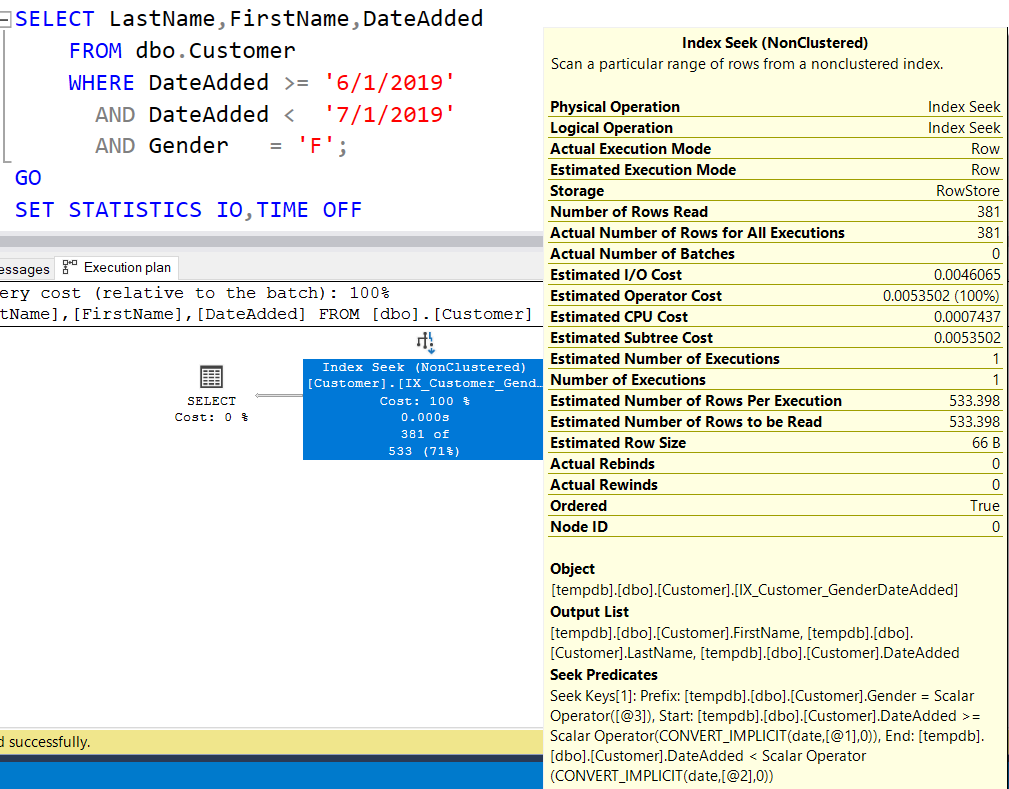
то увидим, что теперь мы имеем и Gender, и DateAdded в поисковом предикате (Seek Predicate), который, наиболее вероятно, и вызвал незначительное уменьшение стоимости запроса.
Заключение
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
SQL-Ex blog
Новости сайта «Упражнения SQL», статьи и переводы
Селективность предиката и структура индекса
Незаконченные дела
Управление индексами
Давайте возьмем реальный пример и создадим два индекса.
Теперь выполним два идентичных запроса, каждый из которых будет использовать один из этих индексов.
Если выполнить их несколько раз, то можно заметить, что первый запрос будет по кругу завершать выполнение на 50 миллисекунд быстрее, чем второй, хотя они оба имеют почти идентичные планы.
Поиск может выглядеть запутанным, поскольку PostTypeId проявляется и как поиск, и как остаточный предикат. Это связано с сортировкой обоих индексов.
Поиск говорит нам, откуда начинается чтение. Это означает, что мы будем искать строки, начиная с ClosedDate 2018-06-01 и с PostTypeId 1.
Начиная отсюда, мы можем найти более высокие значения PostTypeId, поэтому получаем остаточный предикат, чтобы отфильтровать их.
Вообще говоря, поиск может найти единственную строку или же диапазон строк пока они идут подряд. Когда первый столбец индекса используется для поиска диапазона, мы можем найти начальную точку, но нам потребуется остаточный предикат для последующей проверки других предикатов.
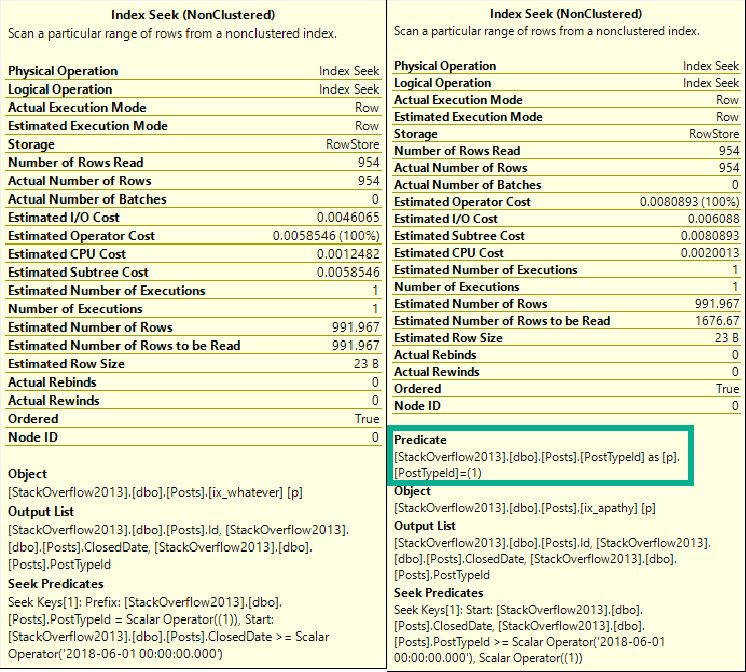 Поисковый скан
Поисковый скан
Имеются также различия в статистике по времени и вводу/выводу.
Помните, как это ломается для каждого предиката:
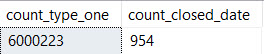
Но ни в каком случае нам не нужны все эти приблизительно 6 миллионов строк PostTypeId 1, чтобы выбрать нужный диапазон ClosedDates.
Снова путаница
Когда это меняется?
Когда мы спроектируем индексы несколько иначе.
Выполняя те же самые запросы, замечаем существенные изменения в первом из них.
Теперь остаточный предикат вредит нам, когда мы ищем диапазон значений.
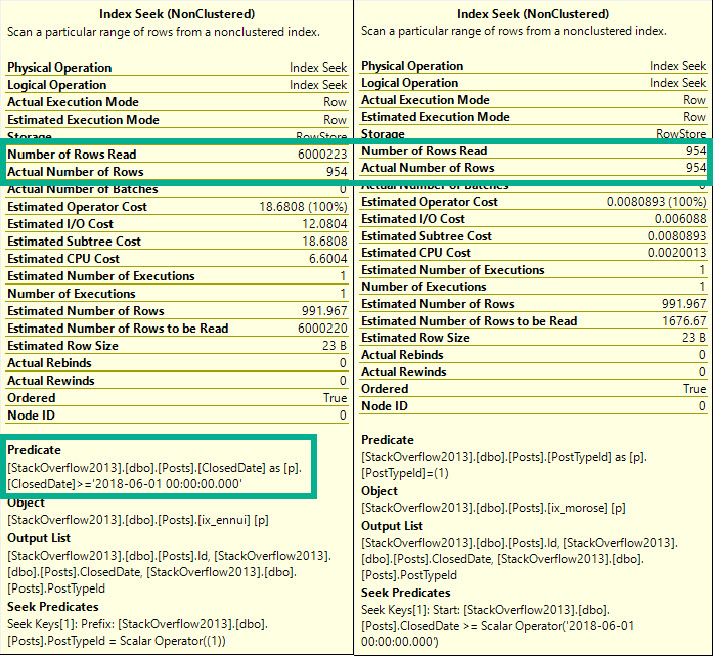
Ошибка на единицу
Иногда подобное также случается, если мы только переставим ключевые столбцы.
Это также отбрасывает предикат диапазона. Мы читаем здесь лишние 30К страниц, поскольку индекс стал больше.
Поиски выглядят здесь идентично тем, когда у меня были столбцы в разделе include индекса.
Что все это значит?
Расположение индексных столбцов, находятся ли они в ключе или в include, могут иметь немалое влияние на чтения, особенно при поиске диапазонов.
Даже если вы имеете неселективный первый столбец, подобный PostTypeId, с предикатом равенства на нем, вам не потребуется читать каждую отдельную строку, которая удовлетворяет фильтру, чтобы применить предикат диапазона, пока этот предикат является поисковым. Когда мы переносим столбец диапазона в Include, или когда добавляем столбец перед ним в ключе, нам приходится делать много лишней работы, чтобы найти нужные строки.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись