Кластеризация и визуализация текстовой информации
В русскоязычном секторе интернета очень мало учебных практических примеров (а с примером кода ещё меньше) анализа текстовых сообщений на русском языке. Поэтому я решил собрать данные воедино и рассмотреть пример кластеризации, так как не требуется подготовка данных для обучения.
Большинство используемых библиотек уже есть в дистрибутиве Anaconda 3, поэтому советую использовать его. Недостающие модули/библиотеки можно установить стандартно через pip install «название пакета».
Подключаем следующие библиотеки:
Для анализа можно взять любые данные. Мне на глаза тогда попала данная задача: Статистика поисковых запросов проекта Госзатраты. Им нужно было разбить данные на три группы: частные, государственные и коммерческие организации. Придумывать экстраординарное ничего не хотелось, поэтому решил проверить, как поведет кластеризация в данном случае (забегая наперед — не очень). Но можно выкачать данные из VK какого-нибудь паблика:
Я буду использовать данные поисковых запросов чтобы показать, как плохо кластеризуются короткие текстовые данные. Я заранее очистил от спецсимволов и знаков препинания текст плюс провел замену сокращений (например, ИП – индивидуальный предприниматель). Получился текст, где в каждой строке находился один поисковый запрос.
Считываем данные в массив и приступаем к нормализации – приведению слова к начальной форме. Это можно сделать несколькими способами, используя стеммер Портера, стеммер MyStem и PyMorphy2. Хочу предупредить – MyStem работает через wrapper, поэтому скорость выполнения операций очень медленная. Остановимся на стеммере Портера, хотя никто не мешает использовать другие и комбинировать их с друг другом (например, пройтись PyMorphy2, а после стеммером Портера).
Исполняемые файлы анализатора для текущей операционной системы будут автоматически загружены и установлены при первом использовании библиотеки.
Создадим матрицу весов TF-IDF. Будем считать каждый поисковой запрос за документ (так делают при анализе постов в Twitter, где каждый твит – это документ). tfidf_vectorizer мы возьмем из пакета sklearn, а стоп-слова мы возьмем из корпуса ntlk (изначально придется скачать через nltk.download()). Параметры можно подстроить как вы считаете нужным – от верхней и нижней границы до количества n-gram (в данном случае возьмем 3).
Над полученной матрицей начинаем применять различные методы кластеризации:
Полученные данные можно сгруппировать в dataframe и посчитать количество запросов, попавших в каждый кластер.
Из-за большого количества запросов не совсем удобно смотреть таблицы и хотелось бы больше интерактивности для понимания. Поэтому сделаем графики взаимного расположения запросов относительного друг друга.
Сначала необходимо вычислить расстояние между векторами. Для этого будет применяться косинусовое расстояние. В статьях предлагают использовать вычитание из единицы, чтобы не было отрицательных значений и находилось в пределах от 0 до 1, поэтому сделаем так же:
Так как графики будут двух-, трехмерные, а исходная матрица расстояний n-мерная, то придется применять алгоритмы снижения размерности. На выбор есть много алгоритмов (MDS, PCA, t-SNE), но остановим выбор на Incremental PCA. Этот выбор сделан в следствии практического применения – я пробовал MDS и PCA, но оперативной памяти мне не хватало (8 гигабайт) и когда начинал использоваться файл подкачки, то можно было сразу уводить компьютер на перезагрузку.
Алгоритм Incremental PCA используется в качестве замены метода главных компонентов (PCA), когда набор данных, подлежащий разложению, слишком велик, чтобы разместиться в оперативной памяти. IPCA создает низкоуровневое приближение для входных данных, используя объем памяти, который не зависит от количества входных выборок данных.
Перейдем непосредственно к самой визуализации:
Если раскомментировать строку с добавлением названий, то выглядеть это будет примерно так:

Не совсем то, что хотелось бы ожидать. Воспользуемся mpld3 для перевода рисунка в интерактивный график.
Теперь при наведении на любую точку графика всплывает текст с соотвествующим поисковым запросом. Пример готового html файла можно посмотреть здесь: Mini K-Means
Если хочется в 3D и с изменяемым масштабом, то существует сервис Plotly, который имеет плагин для Python.
Результаты можно увидеть здесь: Пример
И заключительным пунктом выполним иерархическую (аггломеративную) кластеризацию по методу Уорда для создания дендограммы.
К сожалению, в области исследования естественного языка очень много нерешённых вопросов и не все данные легко и просто сгруппировать в конкретные группы. Но надеюсь, что данное руководство усилит интерес к данной теме и даст базис для дальнейших экспериментов.
Решаем NLP-задачу – как классифицировать тексты по темам?
Расскажем о подходах, позволяющих создать классификатор, автоматически относящий текст к той или иной категории.
В предыдущей статье я рассказал, как подготовить датасет, содержащий тексты блога habr.com с информацией об их принадлежности к определенной категории. Теперь на базе этого датасета я расскажу о подходах, позволяющих создать классификатор, автоматически относящий текст к той или иной категории.
Сегодня нам предстоит описать решение задачи по созданию классификатора текстовых документов. Шаг за шагом мы будем пытаться улучшить нашу модель. Давайте посмотрим, что же из этого получится.
Для решения нашей задачи снова используем язык программирования python и среду разработки Jupyter notebook на платформе Google Colab.
В работе понадобятся следующие библиотеки:
Датасет сохранен в файле формата csv и содержит чуть более 8 тысяч записей. Для работы с ним будем использовать библиотеку pandas – загружаем данные в память при помощи метода read_csv и отображаем на экране несколько первых строк:
Набор данных представляет собой таблицу, в первой колонке которой хранится текст статьи, во второй – присвоенная категория (класс):
Построим «облако слов» для набора данных, чтобы визуально определить наиболее часто встречающиеся слова – это позволит оценить необходимость дополнительной очистки текстов от «мусора», не несущего смысловой нагрузки:
Для необработанного набора данных «облако слов» содержит 243024 уникальных слова и выглядит так:
Попробуем очистить данные:
После небольшой очистки текстов от «стоп-слов» и знаков пунктуации количество уникальных слов снизилось до 142253, а «облако слов» стало более осмысленным:
При желании можно очистить тексты еще более качественно (в реальных задачах так и следует делать), но для обучающего примера датасет уже вполне подходит.
Посмотрим статистику по классам:
Видно, что некоторые классы представлены только одним элементом, а класс «Чулан» составляет более 65% датасета. Для того чтобы работать с более или менее сбалансированным датасетом, выберем тексты только четырех классов:
Разделим датасет на тренировочную, тестовую и валидационную части:
Получили следующее соотношение выборок: X_train – 1136 элементов, X_test – 283 элемента, X_valid – 158 элементов
Для дальнейшей работы понадобится импортировать несколько модулей из библиотеки scikit-learn:
Сначала создадим 2 классификатора (чтобы можно было в дальнейшем сравнить качество получившихся моделей) и обучим их на тестовых данных:
Предскажем получившимися моделями класс текстов в тестовой выборке и сравним метрики:
В связи с тем, что датасет не сбалансирован, метрику «accuracy» (доля верных ответов) использовать нельзя, так как это приведет к завышенной оценке качества работы классификатора. В данном случае самое правильное – считать сразу несколько метрик, устойчивых к распределению классов (в данном случае, это — точность, полнота и f-мера) и смотреть на них все. Однако часто бывает удобно получить не большой набор цифр, а одно число, по которому можно понять, насколько хорошо модель работает. В нашей задаче лучше всего подходит «macro-avg» (сначала подсчитывается каждая метрика по каждому классу, а потом усредняется). Macro-avg более устойчива к скошенным распределениям классов.
Линейный классификатор показал лучший результат на тестовых данных (0,77 против 0,72 у классификатора методом ближайших соседей), поэтому для дальнейшей настройки модели будем использовать его.
На текущий момент классификатор обучен с параметрами по умолчанию. Для большинства задач это вполне приемлемо. Но для более качественной работы модели лучше провести ее дополнительную настройку. В этом случае удобно использовать поиск лучшего сочетания по сетке параметров. Так, можно задать набор значений для параметров классификатора и передать его в модуль GridSearchCV. Он выполнит обучение и оценку модели на каждом сочетании параметров и выдаст лучший результат.
Попробуем улучшить нашу модель, используя различные параметры. Следует иметь в виду, что для доступа к параметрам объекта pipeline необходимо указывать их в виде «название объекта»__«название параметра»:
Обучим модель, используя предложенные параметры (часть из них получила значение по умолчанию, поэтому их указывать не обязательно), и оценим ее качество на тестовых данных:
Русские Блоги
[NLP] Python текстовая кластеризация на английском языке
[Оригинальная ссылка] http://brandonrose.org/clustering
If you have any questions for me, feel free to reach out on Twitter to @brandonmrose
Contents
Но сначала я импортирую все, что мне нужно, заранее (mpld3 не установлен, найдите mpld3 в Anaconda Navigator, выберите Not Installed, нажмите кнопку apply)
For the purposes of this walkthrough, imagine that I have 2 primary lists:
In the full workbook that I posted to github you can walk through the import of these lists, but for brevity just keep in mind that for the rest of this walk-through I will focus on using these two lists. Of primary importance is the ‘synopses’ list; ‘titles’ is mostly used for labeling purposes.
Скопируйте и вставьте https://github.com/brandomr/document_cluster/blob/master/title_list.txt в ваш собственный проект
Скопируйте и вставьте https://github.com/brandomr/document_cluster/blob/master/synopses_list_wiki.txt в свой собственный проект
Скопируйте и вставьте https://github.com/brandomr/document_cluster/blob/master/synopses_list_imdb.txt в ваш собственный проект
Stopwords, stemming, and tokenizing¶
This section is focused on defining some functions to manipulate the synopses. First, I load NLTK’s (Natural Language Toolkit) list of English stop words. Stop words are words like «a», «the», or «in» which don’t convey significant meaning. I’m sure there are much better explanations of this out there.
Next I import the Snowball Stemmer which is actually part of NLTK. Stemming is just the process of breaking a word down into its root.
Below I define two functions:
I use both these functions to create a dictionary which becomes important in case I want to use stems for an algorithm, but later convert stems back to their full words for presentation purposes. Guess what, I do want to do that!
Below I use my stemming/tokenizing and tokenizing functions to iterate over the list of synopses to create two vocabularies: one stemmed and one only tokenized.
Используя эти два списка, я создаю pandas DataFrame со словарным основанным словарным запасом, перечисленным как токенизированные слова. Преимущество этого состоит в том, что он обеспечивает эффективный способ найти основание и вернуть полный токен. Недостатком здесь является то, что токены один-ко-многим: stem’run может ассоциироваться с’ran ‘,’ run ‘,’ running ‘и т.д. маркер.
Вы заметите, что здесь есть определенное повторение. Я мог бы его убрать, но в DataFrame есть только 312209 элементов, что не требует больших накладных расходов (косвенных затрат) при поиске слова на основе ствола по основному индексу.
Tf-idf и сходство документов

Here, I define term frequency-inverse document frequency (tf-idf) vectorizer parameters and then convert the synopses список (сводная коллекция) в матрицу tf-idf.
Чтобы получить матрицу Tf-idf, сначала посчитайте, сколько раз каждое слово появляется в каждом документе. Это преобразуется в матрицу термина документа (dtm, матрица термина документа). Это также просто называют матрицей частоты термина ( Слово частотная матрица). Пример DTM находится здесь справа.
Затем примените термин частотно-обратное взвешивание частоты документа (вес Tf-idf): слова, которые часто встречаются в документе, но не часто в корпусе, получают более высокий вес, поскольку предполагается, что эти слова содержат больше смысла в этом документе.
A couple things to note about the parameters I define below:
termsЭто просто набор функций, используемых в матрице tf-idf. Это словарь
distопределяется как 1-косинусное сходство каждого документа (1-косинусное сходство каждого документа). Сходство косинусов измеряется по матрице tf-idf и может использоваться для генерации метода сравнения сходств между каждым документом и другие документы в наборе документации (каждый синопсис среди синопсов). Вычитая его из 1, получаем косинусное расстояние, которое я буду использовать для рисования на евклидовой (2-мерной) плоскости.
Обратите внимание, что dist Вы можете измерить сходство между любыми двумя или более профилями.
K-означает кластеризацию
Теперь самое интересное: используя матрицу tf-idf, вы можете запустить множество алгоритмов кластеризации, чтобы лучше понять скрытую структуру в синопсисах. Сначала я выбралk-meansK-означает, что нужен бюджет для определения количества кластеров во время инициализации (я выбрал 5). Каждое наблюдение присваивается кластеру (назначение кластера), чтобы минимизировать сумму квадратов в кластере. Далее среднее значение кластерных наблюдений. вычисляется и используется как новый кластерный центроид (центр вращения объекта называется центроидом). Затем наблюдения переназначаются на кластеры и центроиды, пересчитанные в итерационном процессе, пока алгоритм не достигнет сходимости (конвергенции).
I found it took several runs for the algorithm to converge a global optimum as k-means is susceptible to reaching local optima.
Я использую joblib.dump, чтобы выбрать модель (постоянство модели: как правило, обучение модели занимает много времени, поэтому мы обычно сохраняем обученную модель), после того, как она сошлась, и перезагрузить модель / переназначить метки как кластеры.
Здесь я создаю словарь названий, ранжирования, введения, назначения кластера и жанра [ранга и жанра были удалены из IMDB].
I convert this dictionary to a Pandas DataFrame for easy access. I’m a huge fan of Pandas and recommend taking a look at some of its awesome functionality which I’ll use below, but not describe in a ton of detail.
Note that clusters 4 and 0 В нижней части рейтинга, который указывает, что в среднем они содержат фильмы, которые были оценены как «лучше» в списке 100 лучших.
Here is some fancy indexing and sorting on each cluster to identify which are the top n (I chose n= 6) слова, которые являются ближайшими к центроиду кластера. Это дает хорошее представление о теме кластера.
Multidimensional scaling
Вот некоторый код для преобразования матрицы dist (матрицы, которая возвращает расстояние: вычисление расстояния между каждой точкой в матрице и каждой точкой в другой матрице) в двумерный массив, используяmultidimensional scaling. I won’t pretend I know a ton about MDS, but it was useful for this purpose. Another option would be to use principal component analysis.
Visualizing document clusters
In this section, I demonstrate how you can visualize the document clustering output using matplotlib and mpld3 (a matplotlib wrapper for D3.js).
First I define some dictionaries for going from cluster number to color and to cluster name. I based the cluster names off the words that were closest to each cluster centroid.
Next, I plot the labeled observations (films, film titles) colored by cluster using matplotlib. I won’t get into too much detail about the matplotlib plot, but I tried to provide some helpful commenting.

The clustering plot looks great, but it pains my eyes to see overlapping labels. Having some experience with D3.js I knew one solution would be to use a browser based/javascript interactive. Fortunately, I recently stumbled upon mpld3Оболочка matplotlib для D3. Mpld3 в основном позволяет использовать синтаксис matplotlib для создания веб-интерактивов и имеет действительно простой высокоуровневый API для добавления плагина всплывающей подсказки при наведении курсора мыши, что меня и интересует.
Here is the actual creation of the interactive scatterplot. I won’t go into much more detail about it since it’s pretty much a straightforward copy of one of the mpld3 examples, though I use a pandas groupby to group by cluster, then iterate through the groups as I layer the scatterplot. Note that relative to doing this with raw D3, mpld3 is much simpler to integrate into your Python workflow. If you click around the rest of my website you’ll see that I do love D3, but for basic interactives I will probably use mpld3 a lot going forward.
Note that mpld3 lets you define some custom CSS, which I use to style the font, the axes, and the left margin on the figure.

Hierarchical document clustering
Now that I was successfuly able to cluster and plot the documents using k-means, I wanted to try another clustering algorithm. I chose the Ward clustering algorithm because it offers hierarchical clustering. Ward clustering is an agglomerative (This is a «bottom up» approach) clustering method, meaning that at each stage, the pair of clusters with minimum between-cluster distance are merged. I used the precomputed cosine distance matrix (dist) to calclate a linkage_matrix, which I then plot as a dendrogram.
Note that this method returned 3 primary clusters, with the largest cluster being split into about 4 major subclusters. Note that the cluster in red contains many of the «Killed, soldiers, captain» films. Braveheart and Gladiator are within the same low-level cluster which is interesting as these are probably my two favorite movies.

Обработка естественного языка

Mar 14 · 9 min read

Обработка естественного языка или NLP (от англ. Natural language processing) — одна из самых известных областей науки о данных. За последнее десятилетие она приобрела большую популярность как в промышленных, так и в академических кругах.
Но правда в том, что NLP — это далеко не новая область. Стремление человека к тому, чтобы компьютеры понимали наш язык, существовало с момента их создания. Да, те старые компьютеры, которые с трудом могли запустить несколько программ одновременно, всё же успели познакомится со сложностью естественных языков.
Естественный язык — э то любой человеческий язык, такой как английский, арабский, русский и т. д. Насколько трудно сделать так, чтобы компьютер понимал естественные языки, зависит от их структуры. Более того, когда мы говорим, то часто по-разному произносим слова, наши акценты отличаются, независимо от того, используем ли мы родной язык или иностранный. Мы также часто склонны «жевать» слова во время разговора, чтобы быстрее донести мысль, не говоря уже обо всех сленговых словах, которые появляются каждый день.
Цель этой статьи — пролить свет на историю естественной обработки языка и её подразделы.
Начало развития NLP
Естественная обработка языка — это междисциплинарная область на стыке информатики и лингвистики. Существует бесконечное количество способов, чтобы соединить слова и составить из них предложение. Конечно, не все эти предложения будут грамматически правильными или даже иметь смысл.
Люди могут их различать, но компьютер — нет. Более того, нереально загрузить в него словарь со всеми возможными предложениями на всех возможных языках.
На ранних этапах учёные предлагали разделять любое предложение на набор слов, которые можно обрабатывать индивидуально, что гораздо проще, чем обрабатывать предложение целиком. Этот подход аналогичен тому, с помощью которого обучают новому языку детей и взрослых.
Когда мы только начинаем учить язык, нас знакомят с его частями речи. Для примера возьмём английский язык. В нём есть 9 основных частей речи: существительные, глаголы, прилагательные, наречия, местоимения, артикли и др. Эти части речи помогают понять назначение каждого слова в предложении.
Однако недостаточно знать категорию слова, особенно для тех, которые могут иметь более одного значения. Например, слово «leaves» может быть формой глагола « to leave» (англ. уходить) или формой множественного числа существительного «leaf» (англ. лист).
Поэтому компьютерам необходимо базовое понимание грамматики, чтобы обращаться к ней в случае замешательства. Таким образом появились правила структуры фраз.
Они представляют собой набор правил грамматики, по которым строится предложение. В английском языке оно образуется с помощью именной и глагольной группы. Рассмотрим предложение: « Anne ate the apple» (англ. Энн съела яблоко). Здесь « Anne» — это именная группа, а « ate the apple» — это глагольная группа.
Различные предложения формируются с использованием разных структур. По мере увеличения количества правил структуры фраз можно создавать дерево синтаксического анализа, чтобы классифицировать каждое слово в конкретном предложении и прийти к его общему значению.
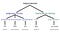
Всё это отлично работает, если предложения просты и ясны. Но проблема в том, что они могут быть достаточно сложными, или в них могут использоваться не совсем однозначные слова или неологизмы. В этом случае компьютерам будет сложно понять, что имелось в виду.
Подразделы NLP
Обработка текста
Чат-боты — один из хорошо известных примеров NLP. Изначально чат-боты были основаны на системе правил. Это означало, что специалисты должны были закодировать сотни, а возможно, и тысячи правил структуры фраз, чтобы чат-бот корректно ответил на данные, которые вводит человек. Таким примером является Eliza. Это чат-бот, разработанный в 1960-х годах и пародирующий диалог с психотерапевтом.
Сегодня большинство чат-ботов и виртуальных помощников создаются и программируются с использованием методов машинного обучения. Эти методы основываются на многочисленных гигабайтах данных, собранных во время разговоров между людьми.
Чем больше данных будет передано модели машинного обучения, тем лучше будет работать чат-бот.
Распознавание речи
Чат-боты про то, как компьютеры понимают письменный язык. А что насчёт устной речи? Как компьютеры могут превратить звук в слова, а затем понять их значение?
Распознавание речи — второй подраздел обработки естественного языка. Это тоже совсем не новая технология. Она была в центре внимания многих исследователей в течение последних десятилетий. В 1970-х годах в Университете Карнеги-Меллона была разработана Harpy. Это была первая компьютерная программа, которая понимала 1000 слов.
В то время компьютеры не были достаточно мощными для распознавания речи в реальном времени, если только вы не говорили очень медленно. Это препятствие было устранено с появлением более быстрых и мощных компьютеров.
Синтез речи
Синтез речи во многом противоположен распознаванию речи. С помощью этой технологии у компьютера появилась возможность издавать звуки или произносить слова.
Первым в мире устройством для синтеза речи считается VODER (англ. Voice Operating Demonstrator — модель голосового аппарата). Оно было разработано Гомером Дадли из компании Bell Labs в 1930-х годах. У VODER было ручное управление. С тех пор многое изменилось.
В системах распознавания речи и чат-ботах предложения разбиваются на фонемы. Чтобы произнести определенное предложение, компьютер сохраняет эти фонемы, преобразовывает и воспроизводит.
Такой способ соединения фонем был и остаётся причиной того, что речь компьютера звучит очень роботизировано, поскольку на границах сшивки элементов часто возникают искажения.
Конечно, со временем звучание стало лучше. Использование современных алгоритмов в новейших виртуальных помощниках, таких как Siri, Cortana и Alexa, подтверждает то, что мы далеко продвинулись. Однако их речь по звучанию по-прежнему немного отличается от человеческой.
Заключение
Обработка естественного языка — общее название области, которое охватывает множество подразделов. Во всех них обычно используют модели машинного обучения, в основном нейросети, и данные множества разговоров между людьми.
Поскольку человеческие языки постоянно и стихийно развиваются, а компьютеру нужны чёткие и структурированные данные, при обработке возникают определённые проблемы и страдает точность. Кроме того, методы анализа текстов сильно зависят от языка, жанра, темы — всегда требуется дополнительная настройка. Однако сегодня многие задачи обработки естественного языка всё же решаются с применением глубокого обучения нейронных сетей.
Обработка естественного языка или NLP (англ. Natural Language Processing) — направление на стыке информатики и лингвистики, которое даёт возможность компьютерам понимать человеческий, т. е. естественный язык. Сейчас это одна из самых популярных областей науки о данных. Однако она существует с момента изобретения компьютеров.
Именно развитие техники и вычислительной мощности привело к невероятным достижениям в сфере NLP. Технологии синтеза и распознавания речи становятся такими же востребованными, как и технологии, работающие с письменными текстами. Разработка виртуальных помощников, таких как Siri, Alexa и Cortana, свидетельствует о том, насколько далеко продвинулись учёные.
Так что же необходимо знать, чтобы начать заниматься естественной обработкой языка? Нужна ли степень по информатике?
Чтобы стать специалистом по NLP, никакие степени не понадобятся. Всё, что вам потребуется, это изучить и попрактиковать определённые навыки, а также создать несколько проектов, чтобы подтвердить свои знания.
В начале пути в сфере обработки естественного языка может быть сложно. Объём информации в интернете огромен и может сбивать с толку или вести не туда. Я, как человек, который сам через это прошёл, решила написать статью и поделиться коротким и чётким руководством для старта.
1. Основы лингвистики
По сути, NLP — это про изучение языков. Разработчик пытается объяснить компьютеру, как понимать мудрёную письменную и устную речь человека.
Я занялась NLP, потому что меня всегда интересовали языки и то, как они образовывались и развивались с течением времени. Однако говорить на каком-то языке не означает полностью понимать его логику.
Чтобы иметь прочную основу для начала работы в NLP, необходимо полностью осознавать базовую логику языка, которому вы пытаетесь «научить» компьютер. Этот язык не обязательно должен быть вашим родным. Вы даже можете выучить новый при разработке проекта для его анализа.
Я не имею в виду, что нужно получать степень по лингвистике или что-то в этом роде. Я пытаюсь сказать, что понимание того, как языки решают различные проблемы, может оказаться полезным при разработке и анализе приложений для NLP. Более того, зная о межъязыковом влиянии, вы можете создавать многоязычные приложения.
Я рекомендую начать изучение основ лингвистики для обработки естественного языка с книги Эмили М. Бендер «Основы лингвистики для естественной обработки языка» (англ. Emily M. Bender Linguistic Fundamentals for Natural Language Processing ).
2. Манипуляции со строками
«Язык», на котором вы пытаетесь анализировать и создавать приложения, обычно имеет форму строк. Даже если это приложение для распознавания речи, она всё равно преобразовывается в текст перед анализом.
Поэтому первый шаг, который вам нужно освоить перед погружением в основные техники NLP, — это манипуляции со строками с использованием любого языка программирования.
Если у вас нет опыта программирования, то рекомендую начать с Python. Он широко используется в различных областях науки о данных, включая NLP. Если у вас уже есть опыт программирования на других языках, то освоить манипуляцию со строками не составит труда.
3. Регулярные выражения
После того, как вы освоите операции со строками с помощью встроенных функций на выбранном вами языке программирования, следующим шагом будут регулярные выражения.
Это один из самых мощных и эффективных методов обработки текста. У регулярных выражений своя терминология, условия и синтаксис. Некоторые разработчики рассматривают их как мини-язык программирования. Они помогут обобщить правила и сделать приложения для обработки тестов более эффективными.
4. Очистка данных
Качество результата работы зависит от входных данных. Поэтому важно, чтобы они были подготовлены наилучшим образом. Этот навык применим не только к проектам по NLP, но и ко всем областям науки о данных. Однако подходы к очистке данных различаются в зависимости от задач и целевых результатов.
При подготовке текста к обработке и анализу мы обычно удаляем все знаки препинания. Это помогает улучшить вариативность слов в тексте. Также существуют различные типы слов, например стоп-слова, которые можно удалить для более эффективного анализа.
Три основных шага очистки текста для NLP:
5. Анализ текста
Наконец-то мы подошли к разделу навыков непосредственно из обработки естественного языка. Получив чистый набор данных, вы будете готовы создавать модели и начинать анализировать текст. Но для этого вам нужно немного знать терминологию из NLP.
Вот пять основных навыков и их значение:
6. Основы машинного обучения
Воспользовавшись основными навыками обработки языка, мы получаем корпус — набор данных после очистки текста и выполнения других основных задач NLP. Далее его необходимо проанализировать и извлечь полезную информацию. Для этого понадобится алгоритм машинного обучения.
Давайте рассмотрим два наиболее часто используемых алгоритма:
7. Оценочные метрики
Это очень важный пункт, о котором обычно забывают. Каждый раз, когда вы применяете модель машинного обучения к данным, необходимо оценивать её результаты. Для каждой модели нужны свои метрики.
Вот некоторые из них:
Более подробную информацию вы можете узнать в материалах лекции из Массачусетского университета в Амхерсте (материалы на англ. яз.).
8. Глубокое обучение
Глубокое обучение полезно для определённых задач, требующих нелинейности пространства признаков. Оно предоставляет улучшенные модели с более высокой точностью и качественными результатами.
Один из самых часто используемых методов глубокого обучения в NLP — рекуррентные нейронные сети. К счастью, нет необходимости знать, как реализовать этот алгоритм или множество других, благодаря открытым библиотекам, таким как Keras и Scikit-learn, написанным на языке Python.
А что действительно нужно сделать, так это научиться эффективно использовать алгоритм, изучая его способ работы и узнавая, какие он даёт результаты.
9. Создание проектов
У меня этот шаг под номером 9, но его необходимо выполнять параллельно со всеми предыдущими шагами. Всегда сразу применяйте свои знания на практике. Это единственный способ проверить, насколько вы их усвоили.
При этом, чем больше вы знаете, тем более крутые приложения вы можете создавать. Вот несколько идей, которые можно опробовать, когда у вас будет достаточно знаний.
Таких идей ещё много. Дерзайте.
10. Научные статьи
Все подразделы науки о данных являются активными областями исследований. Как специалисту по данным в целом и специалисту по обработке естественного языка в частности, вам необходимо быть в курсе последних разработок в этой сфере. Единственный способ это сделать — следить за недавно опубликованными научными статьями о NLP.
Мне удобно создавать оповещения в Google Академии о новых публикациях по конкретным темам, которые меня интересуют: я получаю электронное письмо, как только они выходят.
Заключение
Иногда изучение нового навыка или получение новых знаний — довольно сложная задача. Но если не бросать это на полпути, а продолжать практиковаться и постоянно расширять базу знаний, вы достигнете своей цели.
«Мы можем делать всё, что захотим, если будем придерживаться этого достаточно долго», — Хелен Келлер.
Освоение обработки естественного языка может быть трудной задачей из-за огромного количества информации в интернете. Я надеюсь, что эта статья поможет вам сориентироваться в процессе обучения и сделает его немного проще.