Можно ли исключить проверку в середине диапазона в пользу проверок на границах входящих в диапазон

Я не отрицаю спонтанность и озарение в тестировании. Вдохновение и интуицию.
Однако, считаю что полагаться только на них при создании тестов неразумно.
В прошлом я часто выполняла тесты просто так, потому что мне показалось что это может найти баг.
При этом я:
— не всегда понимала что именно проверяю данным тестом
— часто выполняла несколько (или даже много) однотипных тестов
Иногда, когда у меня заканчивается львовский фундук в шоколаде, я становлюсь злобным бендеровцем перфекционистом. И тогда я говорю себе: зачем несколько тестов с цифрами из середины диапазона?
Вы можете ответить? Зачем два, три теста с цифрами из середины диапазона? Что мы проверяем? Можно ли от них вообще отказаться?
Поле для ввода чисел обычно имеет два класса эквивалентности: валидные значения и невалидные.
Ок, границы проверили.
Так нужны ли еще тесты со значениями из середины?
Тем не менее, большинство тестировщиков берут хотя бы одно значение из середины. И не могут объяснить почему. Ну, так, берем на всякий случай.
Именно из за этой гипотетической разницы мы выполняем дополнительный тест (или несколько). Ведь если поведение на границах и в середине может отличаться, то правильность поведения на границах не гарантирует правильность поведения в середине диапазона.
Так что это не интуиция нас призывает эти тесты делать, а логика.
Здесь, однако, техника классов эквивалентности («все значения из класса эквивалентны») вступает в конфликт с техникой граничных значений («поведение на границах может отличаться»). Конфликт этот чаще всего решают путем добавления дополнительного теста (из середины).
Также, границы и около них я обычно тестирую только в первой-второй итерации после появления фичи. Когда проверка этой фичи переходит в категорию регрессионной, тесты на границы я могу отбросить (если логика фичи позволяет), а значение из середины диапазона использовать в дымовом тестировании.
Также, значение из середины я беру потому, что в основных сценариях использования фичи юзеры чаще вводят значения из остальной части класса, а не граничные (моя личная статистика).
Тестирование программного кода (тестовые примеры)
4.1.2.1. Граничные условия
Для еще большей уверенности в работоспособности системы используют пять тестовых примеров:
Такой способ проверки называется проверкой на граничных значениях. Такая проверка позволяет выявлять проблемы, связанные с выходом за границы диапазона. Например, если в функцию
4.1.3. Проверка робастности (выхода за границы диапазона)
Для тестирования робастности к тестовым примерам, рассмотренным в предыдущем разделе, добавляются еще два тестовых примера:
проверяющие поведение системы за границей допустимого диапазона, а также в случае тестирования операций сравнения дополнительно дающие гарантию того, что в них не допущена опечатка.
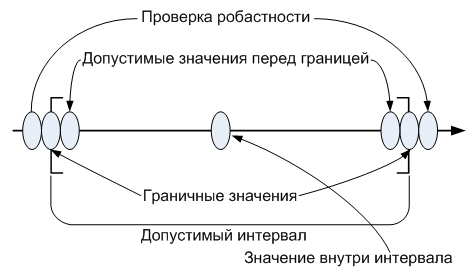
В литературе часто встречается утверждение, что значение внутри интервала является избыточным и его тестирование не требуется. Однако, проверка внутреннего значения является полезной как минимум с психологической точки зрения, а также в случае, если интервал ограничен сложными граничными условиями. Также рекомендуется отдельно проверять значение 0 (даже если оно находится внутри интервала), т.к. зачастую это значение обрабатывается некорректно (например, в случае деления на 0).
4.1.4. Классы эквивалентности
При разработке тестовых примеров может возникнуть такая ситуация, в которой различные входные значения приводят к одним и тем же реакциям системы. Если при этом такие входные значения имеют что-то общее, то возможно объединение таких значений в классы эквивалентности, т.е. выполнение эквивалентного разбиения множества допустимых входных значений.
Рассмотренные выше граничные условия могут служить примером классов эквивалентности:
При определении классов эквивалентности следует руководствоваться следующими правилами:
Другим примером разбиения на классы эквивалентности может служить тестирование открытия файла по его имени. В результате тестирования необходимо определить, все ли варианты имен обрабатываются системой согласно следующим тест-требованиям.
Можно выделить следующие классы эквивалентности:
Эти классы эквивалентности иллюстрируют, что проверки на границах интервалов применимы не только для тестирования арифметических операций и операций сравнения. Практически для любых данных, даже текстовых, можно определить «минимальные» и «максимальные» допустимые значения.
33 тестера
суббота, 27 июля 2013 г.
Техники анализа классов эквивалентности и граничных значений
Техника анализа классов эквивалентности
Определение
Наверное, вы догадываетесь, что полное тестирование даже простой программы невозможно. А если и возможно, но займет много лет.
Давайте договоримся о том, какие тесты мы будем считать эквивалентными.
Как можно использовать технику
Давайте перейдем от теории к практике.
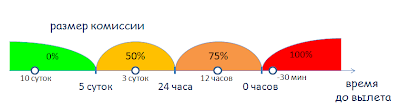
Поэтому тестировщик должен подходить к разбиению на классы эквивалентности очень ответственно.
Техника анализа граничных значений
Давайте теперь вернемся к нашему примеру с бронированием и проведем тестирование граничных значений.
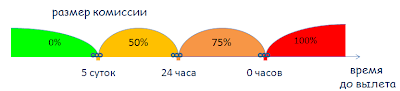
Опять же, мы рассмотрели очень простой пример, в реальных продуктах обычно граничные значения найти сложнее.
Как мы уже говорили, о техниках анализа классов эквивалентности и граничных значений вы можете почитать почти во всех книгах по тестированию. Все-таки, это основные техники тест дизайна.
Для тренировки, можете выбрать любое приложение, попробовать выделить его входные переменные, разбить их на классы эквивалентности, выделить границы классов, затем составить тесты, используя техники анализа классов эквивалентности и граничных значений.
Всем спасибо за внимание! Буду ждать ваших вопросов и замечаний в комментариях!
22 комментария:

Спасибо, Елена! Про эквивалентность тестов и входных параметров я писал в разделе Эквивалентные тесты, но лучше бы это было сделать в начале, согласен с вами!
Далее по тексту:
«мы можем выбрать разные принципы разбиения на классы эквивалентности:
• По количеству символов
• По типу символов (цифры, буквы, спец символы)
«
А тут вроде уже вроде классы выделяются из множества строк (т.е. входных данных), которые можно ввести в поле.
Теперь пример.
Вы выделяете подмножества из множества (чего? видимо, тестов). Хорошо б тогда это множество очертить/определить.
И еще. Вот этот момент:
«Слишком большое количество эквивалентных классов увеличивает вероятность, что большинство тестов будет лишним (избыточным)».
А как может получится, что выделено много лишних классов?
> А тут вроде уже вроде классы выделяются из множества строк (т.е. входных данных), которые можно ввести в поле.
Наверное я слишком вольно и неявно использовал переходы от эквивалентности классов к эквивалентности входных значений, что вас и запутало 🙁
> «Слишком большое количество эквивалентных классов увеличивает вероятность, что большинство тестов будет лишним (избыточным)».
А как может получится, что выделено много лишних классов?
Спасибо вам за советы! Я еще только учусь писать, так что ваши профессиональные замечания приму во внимание.
Привет всем,
Меня зовут мистер Ругаре Сим. Я живу в Голландии и я счастливый человек сегодня? и я сказал себе, что любой кредитор, который спасет меня и мою семью от нашей бедной ситуации, я отошлю к любому человеку, который ищет кредит для него, он дал счастье мне и моей семье, я нуждался в кредите в размере € 300 000.00, чтобы начать свою жизнь заново, так как я отец-одиночка с двумя детьми. Я встретил этого честного и опасающегося у Аллаха кредитора, который помог мне с ссудой в 300 000 евро, он боится Аллаха, если вам нужен кредит и вы вернете кредит, пожалуйста, свяжитесь с ним и скажите ему, что (мистер Ругаре Сим) направит вас к нему. Свяжитесь с г-ном Мохамедом Кареном по электронной почте: (arabloanfirmserve@gmail.com)
> «К минусам можно отнести то, что при неправильном использовании техники мы рискуем потерять баги.» Может быть рискуем что определенная функция будет не проверена? Или проверена, но не полностью?
Да, вы правы, и из-за того, что определенная функция не будет проверена или проверена не полностью, мы рискуем потерять баги. Вернее даже не потерять, а пропустить.
> «Если техника анализа классов эквивалентности ориентирована на тестовое покрытие, то эта техника основана на рисках. Эта техника начинается с идеи о том, что программа может сломаться в области граничных значений.» А эквивалентные классы говорят о том что программа может одинаково не работать при любом значении из определенного диапазона? Так в чем же принципиальная разница?
> «Если следовать этой рекомендации, то в нашем случае останется 9 тестов.» Почему 9, а не 7? Одно значение в пределах класса, одно на границе.
Я считал так: по 3 теста на каждую границе (тот минимум, который нужен для использования предписания техники анализа граничных значений для проверки значений на границе, до границы, и после границы). А 7 тестов получается, если проверять значения на границах и не проверять все значения вокруг границ (хотя при этом мы покрываем все классы эквивалентности).
Спасибо большое за ваши замечания и вопросы, Евгений! Вы мне здорово помогаете! Надеюсь вы будете так же активно комментировать мои сообщения и дальше!
Тестирование областей определения или нечто большее, чем анализ граничных значений

Все тестировщики как минимум наслышаны о таких техниках тест-дизайна, как классы эквивалентности и анализ граничных значений. Казалось бы, что может быть проще: выделить классы, взять по одному значению в каждом, проверить границы классов и значения слева и справа от границ. Но всегда ли дела обстоят настолько просто? Как быть, если после разбиения на классы оказывается, что с границами, в общем-то, проблема — их нельзя определить, поскольку данные невозможно упорядочить? Что если тестируемые параметры связаны между собой некоей логикой и зависят друг от друга? Сколько тестов достаточно? Ниже будут рассмотрены возможности двух основных техник тест-дизайна, превышающие те, что заложены в их непосредственном определении.
Область определения — математический термин — совокупность всех возможных значений переменной. Тестирование областей определения рассматривает программу как функцию многих переменных, каждая из которых принимает конечное множество значений. Каждое такое множество можно разбить как минимум на два класса эквивалентности — валидные и невалидные значения.
Классы эквивалентности
Типичные ошибки этого этапа тестирования областей определения: слишком много или слишком мало классов, классы выделены неправильно (по отношению к функциональности программы).
Выбор значений
Сочетания значений
Дефекты, зависящие от входных данных, можно поделить на те, которые возникают при конкретном значении одного параметра, и те, для возникновения которых нужно сочетание конкретных значений более чем одного параметра. Для обнаружения последних применяют комбинаторные техники тестирования, одной из которых является попарное тестирование (pairwise).
Очевидно, что при использовании сильного и/или надежного комбинирования количество тестов будет резко возрастать при увеличении количества значений какого-либо из параметров и, конечно, при увеличении количества самих параметров. Техника попарного перебора (pairwise) — один из способов уменьшить количество тестов, при этом попытавшись сохранить качество тестирования, т.е. свести к минимуму количество необнаруженных ошибок. Но применяя эту технику, важно понимать, что ошибки на стыке более чем двух значений параметров останутся ненайденными.
Другой способ уменьшить количество тестов — узнать, есть ли зависимости между входными параметрами, и учесть это в тестах. Это возможно далеко не всегда: часто тестирование черного ящика не позволяет «заглянуть внутрь». В этом случае можно попытаться выявить зависимости эмпирически и учесть их в комбинаторных тестах. Однако, есть риск ошибиться при выделении таких закономерностей.
Комбинаторные тесты можно и нужно составлять с помощью соответствующих инструментов, чтобы избежать человеческого фактора.
Искренне надеюсь, что вышеизложенное поможет вам проектировать эффективные тесты.
Можно ли исключить проверку в середине диапазона в пользу проверок на границах входящих в диапазон








Что пишут в блогах
Продолжу хвастаться статусом книги.
I’m sticking with “bug” rather than adopt another word such as “fault,” which is the current fad in publications because:

Онлайн-тренинги
Что пишут в блогах (EN)
Разделы портала
Про инструменты

Автор: Юлия Миронова, ведущий специалист компании «Лаборатория качества»
Самый первый метод тест-анализа, который каждый начинающий тестировщик постигает инстинктивно, – это метод граничных значений. Но так ли он прост, как это кажется на первый взгляд? Давайте разберемся!
Для сравнения разных подходов возьмем конкретный пример. Пусть у нас на сайте есть форма предварительного расчета стоимости страховки жизни, базирующаяся на очень простой формуле. Клиент вводит возраст и сумму в рублях, на которую он хочет застраховать свою жизнь. Если клиент моложе 18 лет или старше 60, выводится сообщение: «К сожалению, на данный момент у нас нет для вас подходящих предложений». Во всех остальных случаях мы просто считаем процент от введенной суммы; этот процент равен возрасту клиента. Да, я знаю, что в реальности расчет будет гораздо сложнее, но для наших целей такая модель подойдет.
Что нам говорит здравый смысл
Итак, любой новичок, который буквально пару дней придумывает тесты, сразу понимает, что нужно как-то проверить условия 18 и 60 лет. Скорее всего, для надежности он выберет (17, 18, 19 лет) и (59, 60, 61 год). И это хороший выбор! Действительно, если сбой есть хоть на каких-то значениях, то его будет видно и около границы с той или другой стороны. Более того, сбой чаще всего проявляется именно на самих граничных значениях.
Что нам говорит определение ISTQB FL
Теперь посмотрим, что нам рекомендует такой надежный источник, как Силлабус ISTQB FL: «Минимальные и максимальные значения сегмента являются граничными значениями. Граничное значение для валидного сегмента является валидным граничным значением, для невалидного сегмента – невалидным». Другими словами, мы имеем тут три диапазона (… по 17, от 18 до 60, от 61 и выше) и только по два значения на каждую границу (17, 18 и 60, 61). Именно такой ответ будет требоваться на экзаменах ISTQB, и это часто сбивает с толку новичков, которым хочется проверить границы со всех сторон.
Определенная логика в подходе составителей Силлабуса есть: если на 18 и 60 годах система правильно посчитала процент, то ожидать, что на 19 и 59 она вдруг опять покажет ошибку «ваш возраст нам не подходит», было бы странно. Точнее, ошибка на этих значениях возникнуть может, но с такой же вероятностью, как и на любых других числах диапазона (а мы уже решили, что такая вероятность невысока).
Что нам говорит Ли Копленд про тестирование границ
Теперь давайте обратимся к классику тест-анализа Ли Копленду и его известной книге «A Practitioner’s Guide to Software Test Design», которая, к сожалению, не переводилась на русский. Заглянув в раздел «Граничные значения», мы увидим все то же решение, первым приходящее в голову: (граница — 1), граница, (граница + 1). Кстати, именно у Копленда вы можете прочитать подробное обоснование того, почему ошибки в коде чаще всего заметны на границах диапазона и очень редко встречаются на одиноком случайном значении внутри диапазона.
При этом в разделе «Доменный анализ» (термин можно понимать как «Анализ диапазонов», используется он для случаев учета границы не у одного параметра, а у двух и более) терминология резко меняется. Появляются такие понятия как ON, OFF, IN и OUT. Чтобы понять, откуда они взялись, и почему их четыре, нам понадобится ознакомиться с предысторией вопроса.
На заре эры тестирования некоторые параметры программы были просты, как выключатели. Например, человек вводил ответ на тест – число, правильным ответом было 10. На ввод всех прочих чисел система должна была писать «неверно», а на 10 – «молодец». Для таких параметров ввели первые очень простые границы – ON/OFF. ON – это в данном случае 10, то есть значение или граница, на котором выключатель включился. Все остальные значения попадали в OFF. Другие параметры могли быть сложнее, и результаты стали задаваться не просто точкой, а целыми интервалами. Скажем, в нашем примере клиент мог застраховать жизнь при возрасте 18 до 60 лет – следовательно, появились границы IN/OUT (внутри и вне диапазона). Все числа от 18 до 60 попадали в IN, остальные – в OUT.
Пока все было логично, но появилась новая проблема: теперь названия границ могут быть разными в разных параметрах. А если параметр работает как выключатель, но в двух точках? А если есть и точка и интервал? В конечном итоге все эти 4 границы решили определить для любого параметра; тестировщикам предоставлялся выбор конкретного варианта.
Были приняты такие определения (они фигурируют и в книге Копленда), которые мы проиллюстрируем числами из нашего примера:
Итак, для применения метод «доменного анализа» к нашему примеру нам потребуется установить ограничения и на сумму в рублях, которую вводит пользователь. Предположим, что эта сумма будет не меньше 100 000 рублей, но не больше 2 000 000. Во всех остальных случаях мы тоже пишем «К сожалению, на данный момент у нас нет для вас подходящих предложений». Сами по себе границы нам понятны:
Правда, хорошо, что у нас нет копеек? Здесь, кстати, я хотела бы сделать первую ремарку.
В нашем примере все числа целые, так что попробуем использовать метод Копленда и составить таблицу доменного анализа так, чтобы проверить границы обоих параметров.
В соответствии с методикой нельзя совмещать два ON, ON и OFF или два OFF, ведь такое совмещение при падении теста усложнит локализацию, особенно если тесты подлежат автоматизации. Тем не менее иногда такие тесты делают специально (например, «нарушить границы в нескольких полях в форме и проверить, что система покажет все сообщения об ошибках разом»). Мы пока все делаем строго по методике и проверяем все границы по одной. В первую очередь расставляем все значения ON и OFF, которые нам надо проверить. Получается восемь тестов:

Мы не можем провести тесты, указав только одно значение, поэтому теперь везде, где не хватает значения, мы ставим недостающее IN. Пусть для возраста это будет 40, а для суммы – 200 000 рублей.
Вот мы и получили 8 тестов для проверки границы уже не одного, а сразу двух параметров, имеющих ограниченные позитивные диапазоны:

Уверена, что при взгляде на эту таблицу вам инстинктивно хочется добавить девятый тест, в котором оба значения – IN. Но Копленд рассматривает именно проверки границ, а тесты, где все значения IN, к граничным не относятся.
А теперь десерт!

Что делать, если диапазон и границы заданы не только для входных параметров, но и для итога работы программы?
Вот реальные примеры:
Дата окончания договора рассчитывается автоматически от даты заключения с добавлением продолжительности договора. При этом в зависимости от года окончания договора он хранится в разных хранилищах и имеет разные условия расторжения.
Программа обработки изображений позволяет изменить качество и размер изображения, но если у выходного изображения размер будет больше 3 MB или произведение сторон будет больше 16 мегапикселей, то получить изображение можно будет только как внешнюю ссылку на хранилище.
Назначенные в таск-трекере на одного человека задачи не должны превышать 8 часов за сутки (или уж хотя бы 24 часа за сутки, так и быть!).
То есть, мы изначально имеем границы на результат обработки данных, но при этом для тестирования указываем значения только тех параметров, которые можем напрямую задать программе. Получается, что результат зависит от параметров, имеющих собственные границы. Кроме того, иногда в обработке возникают и промежуточные этапы; параметры на этих этапах также могут иметь промежуточные значения.
Для наглядности давайте вернемся к нашему примеру и введем дополнительное ограничение: мы не хотим связываться с теми, кто заплатит нам за страховку меньше 50 000 рублей, они также получат сообщение «К сожалению, на данный момент у нас нет для вас подходящих предложений».
Как нам составить набор тестов для такого случая? Вновь используем технику «доменного анализа» Копленда, но теперь таблица станет чуть-чуть сложнее: у нас появится еще один параметр «к оплате». Сначала, как и прошлый раз, расставим все значения ON и OFF, которые нам надо проверить. Добавляем два дополнительных граничных теста для значения «к оплате»:

Мы не можем провести тесты, указывая только одно значение или вообще ничего не вводя. Нам снова надо заполнить недостающие данные, но теперь у нас нет возможности сделать это произвольно. Дело в том, что значение параметра «к оплате» у нас равно проценту от суммы, которую ввел клиент, а этот процент равен его возрасту.
Если мы (как в прошлый раз) подставим сумму 200 000 рублей и возраст 40 лет, а потом посчитаем, то у нас получится куча тестов либо с двумя OFF, либо с совпадением ON и OFF. Как мы помним, это совершенно недопустимо!

А ведь мы еще даже не начали указывать значения суммы и возраста для двух последних тестов, но и их тоже нельзя брать наугад – они должны дать нам именно наши граничные значения параметра «К оплате»! Что же делать?
Вообще говоря, мы можем использовать обычный метод тыка: сдвигать по чуть-чуть значения суммы и возраста до тех пор, пока не попадем в нужный нам диапазон. Копленд предлагает другое решение.
Давайте нарисуем график зависимости параметра «к оплате» от суммы и возраста и отметим на графике наши границы. Красная кривая показывает нам область, где параметр «к оплате» будет равняться 50 000 рублей. Пары значений ниже этой линии брать нельзя (то есть, для возраста 18 мы сразу видим, что сумма должна быть больше 282 000 рублей).

Теперь, глядя на этот график, мы легко выберем те граничные значения, которые нам подойдут, и получим, например, такой набор тестов:

Как видите, все границы всех диапазонов проверены. Более того, нам удалось выполнить правило «в тесте может быть только одно значение OFF или ON, а все остальные обязательно должны быть IN».
Теперь я бы хотела сделать вторую ремарку.
Итак, я надеюсь, что теперь, разобрав разные школы и подходы к тестированию границ, вы убедились: метод этот хоть и не столь прост, как кажется на первый взгляд, но все-таки крайне полезен для начинающего тест-аналитика. Я рекомендую сначала освоить все перечисленные мной методы, а потом определить тот, который выгоднее всего использовать именно на вашем проекте.