Можно ли коррелировать данные полученные в разных шкалах без их преобразований
Группа: Пользователи
Сообщений: 1
Регистрация: 13.08.2009
Из: Харьков
Пользователь №: 6190
![]()
Всем доброго времени суток!
Помогите, пожалуйста, в следующей проблеме: есть результаты выборки по 50 тестам, которые делятся на 5 категорий по десять тестов в каждой. Я хочу получить значение выборки для каждой категории отдельно взяв среднее по соответствующим десяти тестам (чтобы использовать их в дальнейшем анализе). Но проблема состоит в том, что в 4 категориях тесты измеряются в 5-ти бальной метрической шкале, и тут все нормально, а в оставшейся категории все тесты измеряются в различных шкалах (при этом,как метрических, так и порядковых). Могу ли я применить к ним какое-нибудь преобразование так, чтобы они тоже стали измерятся в единой шкале (5-ти бальной)? Если да, то какое и как его применить?
И еще есть вопрос с этим связанный: а как влияют линейные преобразования данных на ANOVA и регрессионный анализ? Просто я пробовал применять линейные преобразования в описанной выше ситуации (после чего делал АNOVA и регрессию), и очень сомневаюсь в достоверности и правильности полученных результатов.



 | |
|
Группа: Пользователи
|

| |
|
Группа: Пользователи
|
| |
|
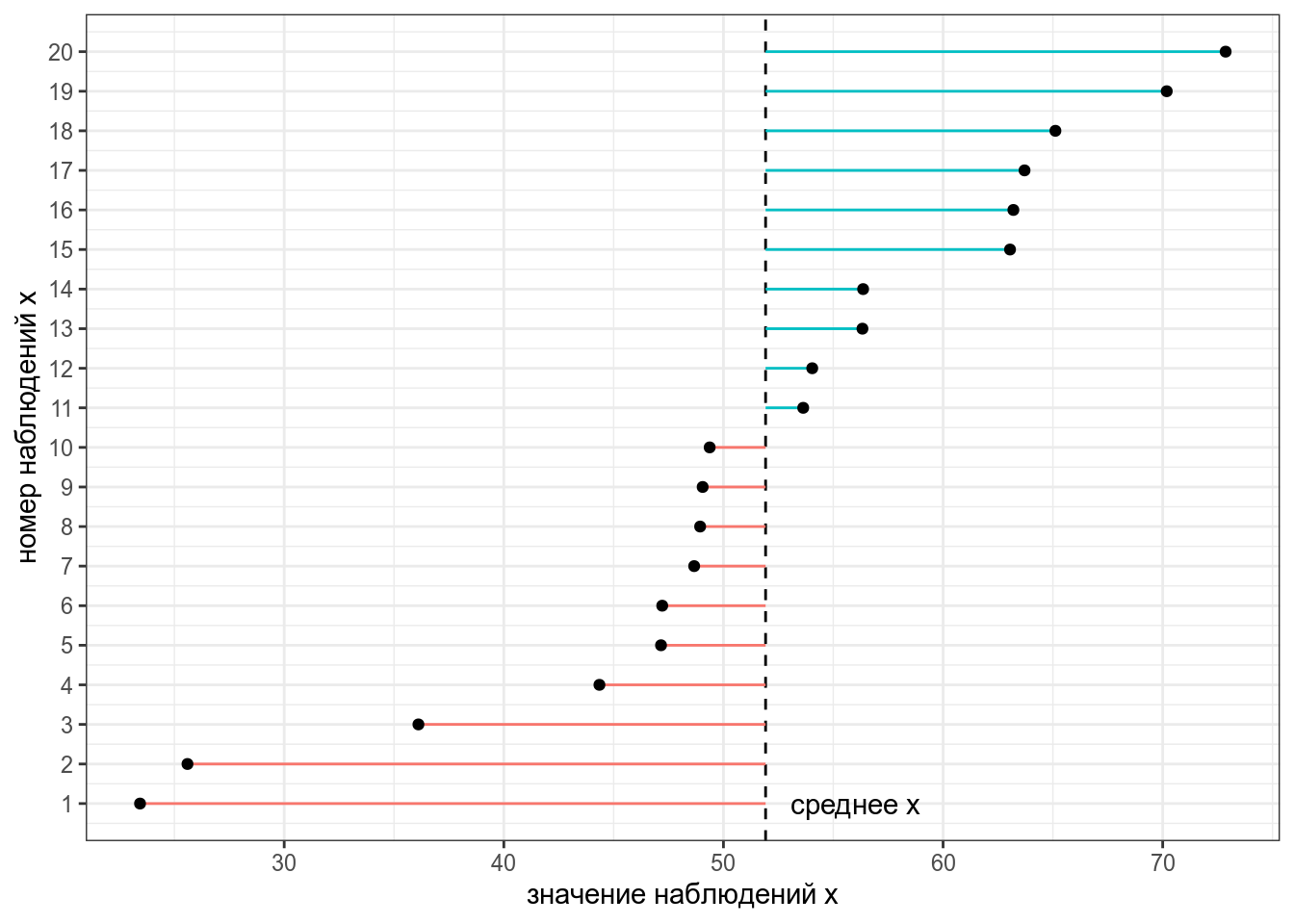
Группа: Пользователи 15 Корреляция и регрессия15.1 Дисперсия и стандартное отклонениеДисперсия — мера разброса значений наблюдений относительно среднего. Представим, что у нас есть следующие данные:
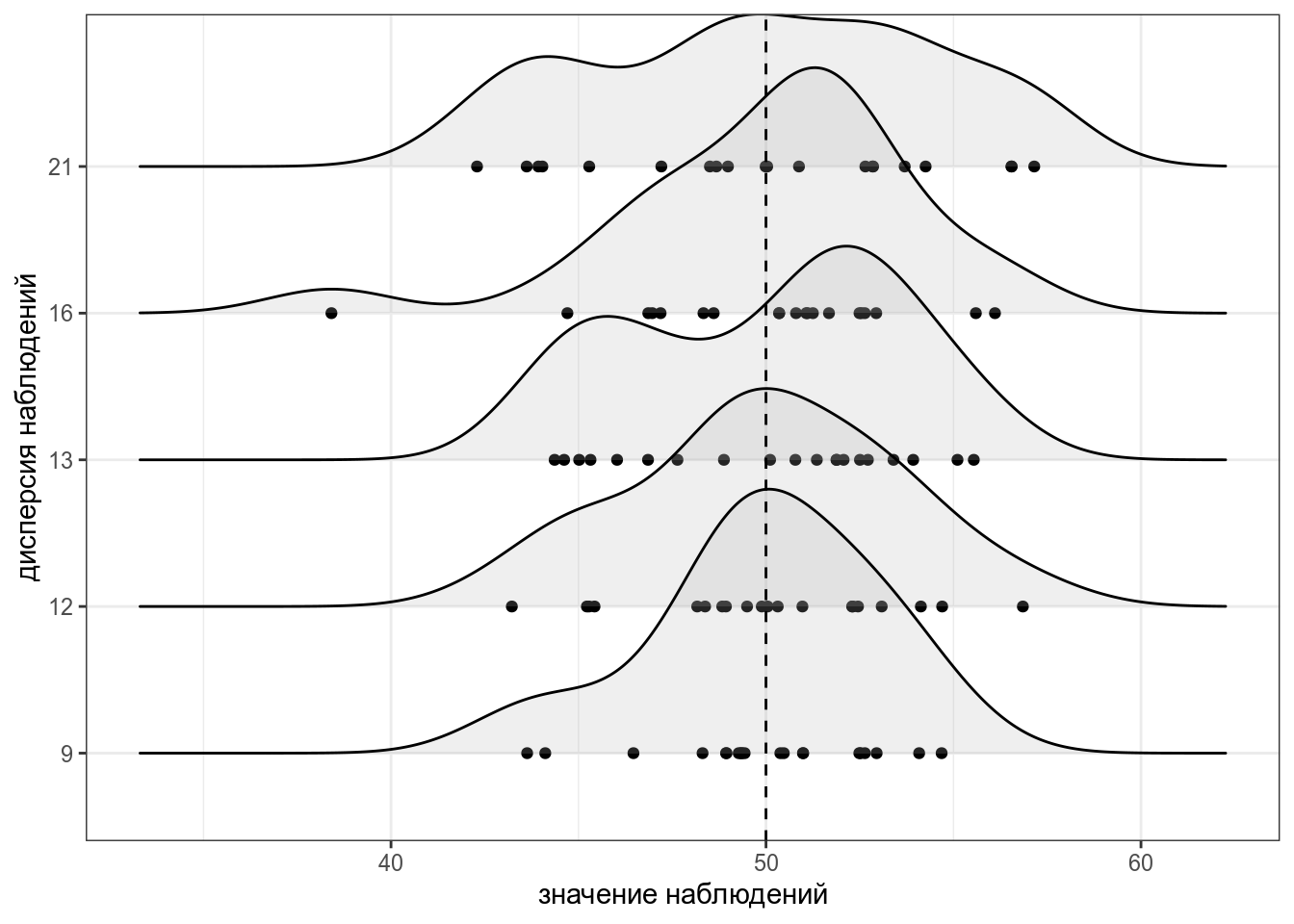
Для того чтобы было понятнее, что такое дисперсия, давайте рассмотрим несколько расспределений с одним и тем же средним, но разными дисперсиями:
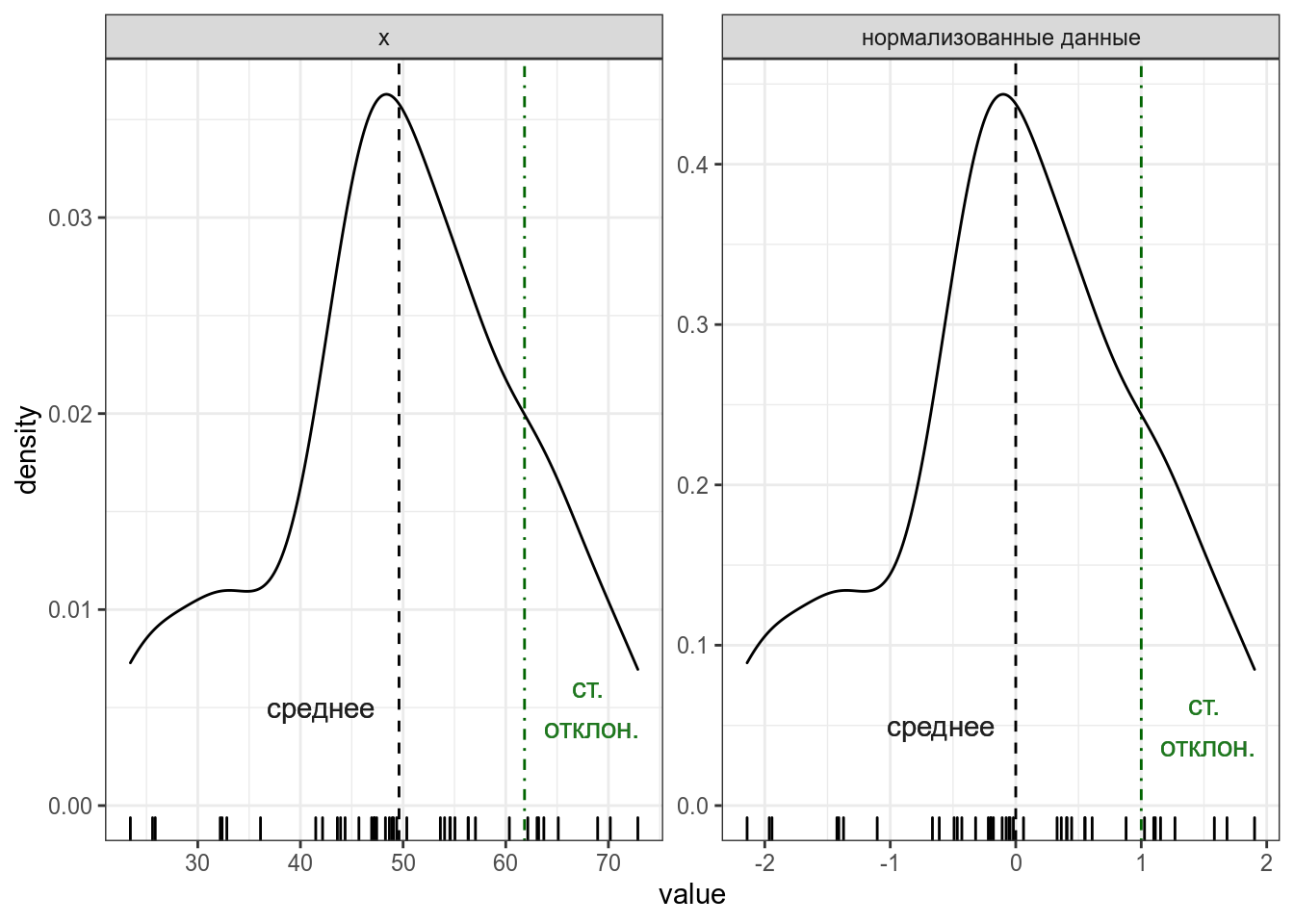
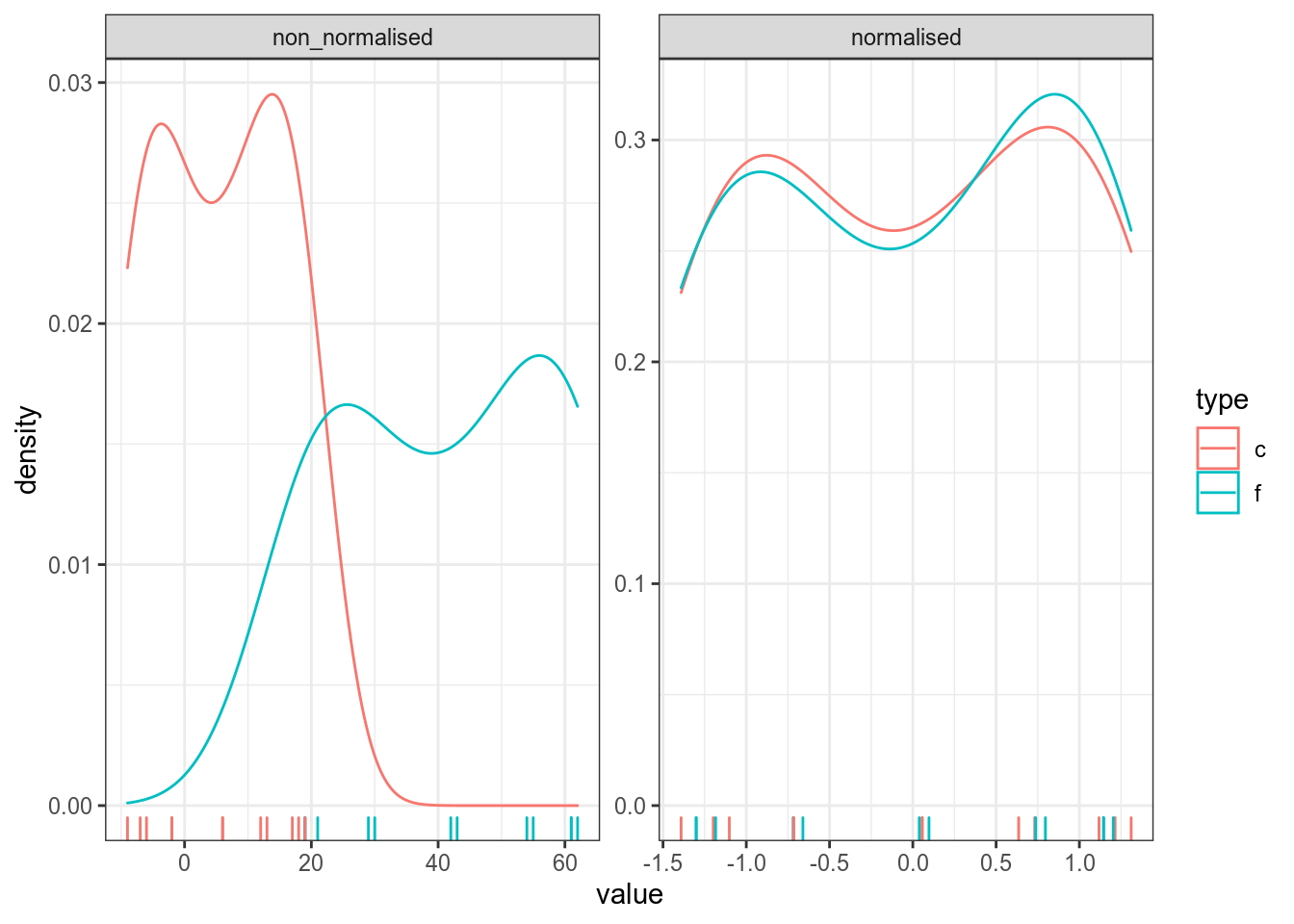
Проверим, что функция выдает то же, что мы записали в формуле. Так как дисперсия является квадратом отклонения, то часто вместо нее используют более интерпретируемое стандартное отклонение \(\sigma\) — корень из дисперсии. В R ее можно посчитать при помощи функции sd() : 15.2 z-преобразованиеz-преобразование (еще используют термин нормализация) — это способ представления данных в виде расстояний от среднего, измеряемых в стандартных отклонениях. Для того чтобы его получить, нужно из каждого наблюдения вычесть среднее и результат разделить на стандартное отклонение. Если все наблюдения z-преобразовать, то получиться распределение с средним в 0 и стандартным отклонением 1 (или очень близко к ним).
Проверим, что функция выдает то же, что мы записали в формуле. Однаждый я заполучил градусник со шкалой Фаренгейта и целый год измерял температуру в Москве при помощи градусников с шкалой Фарингейта и Цельсия. В датасет записаны средние значения для каждого месяца. Постройте график нормализованных и ненормализованных измерений. Что можно сказать про измерения, сделанные разными термометрами?
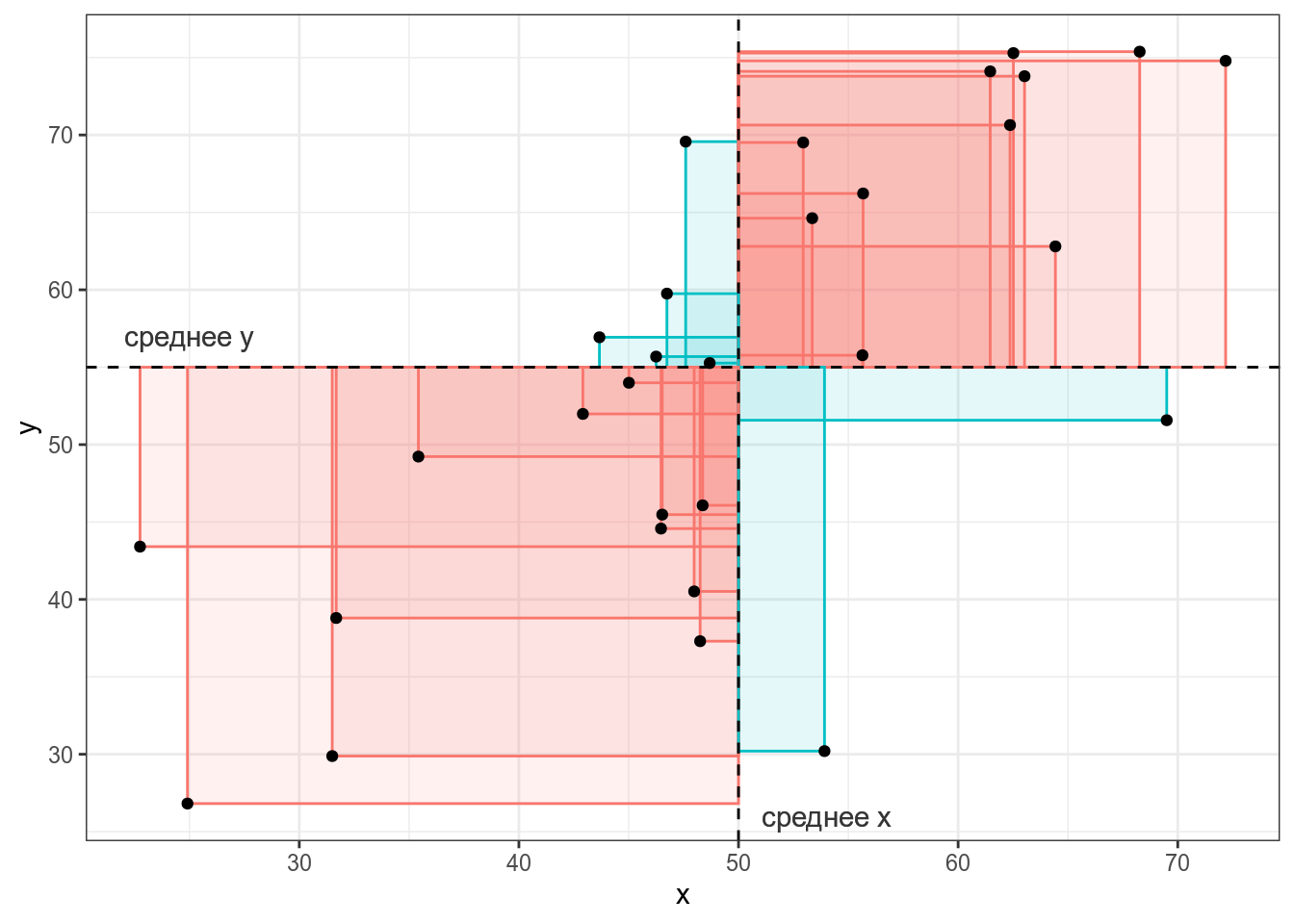
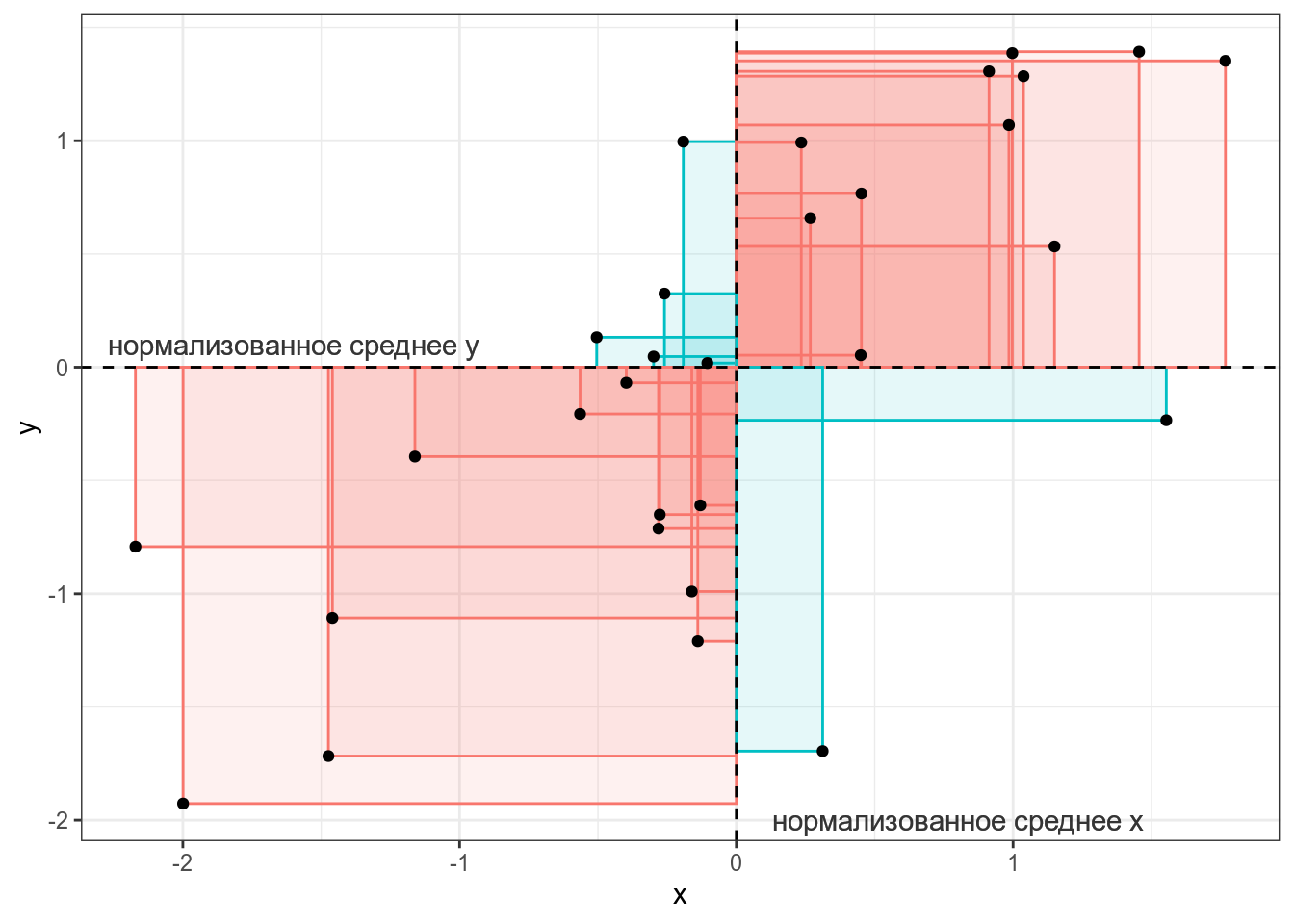
15.3 КовариацияКовариация — эта мера ассоциации двух переменных. Представим, что у нас есть следующие данные:
Тогда, согласно формуле, для каждой точки вычисляется следующая площадь (пуктирными линиями обозначены средние):
Как видно, простое умножение на два удвоило значение ковариации, что показывает, что непосредственно ковариацию использовать для сравнения разных датасетов не стоит. Проверим, что функция выдает то же, что мы записали в формуле. 15.4 КорреляцияКорреляция — это мера ассоциации/связи двух числовых переменных. Помните, что бытовое применение этого термина к категориальным переменным (например, корреляция цвета глаз и успеваемость на занятиях по R) не имеет смысла с точки зрения статистики. 15.4.1 Корреляция ПирсонаКоэффициент корреляции Пирсона — базовый коэффициент ассоциации переменных, однако стоит помнить, что он дает неправильную оценку, если связь между переменными нелинейна.
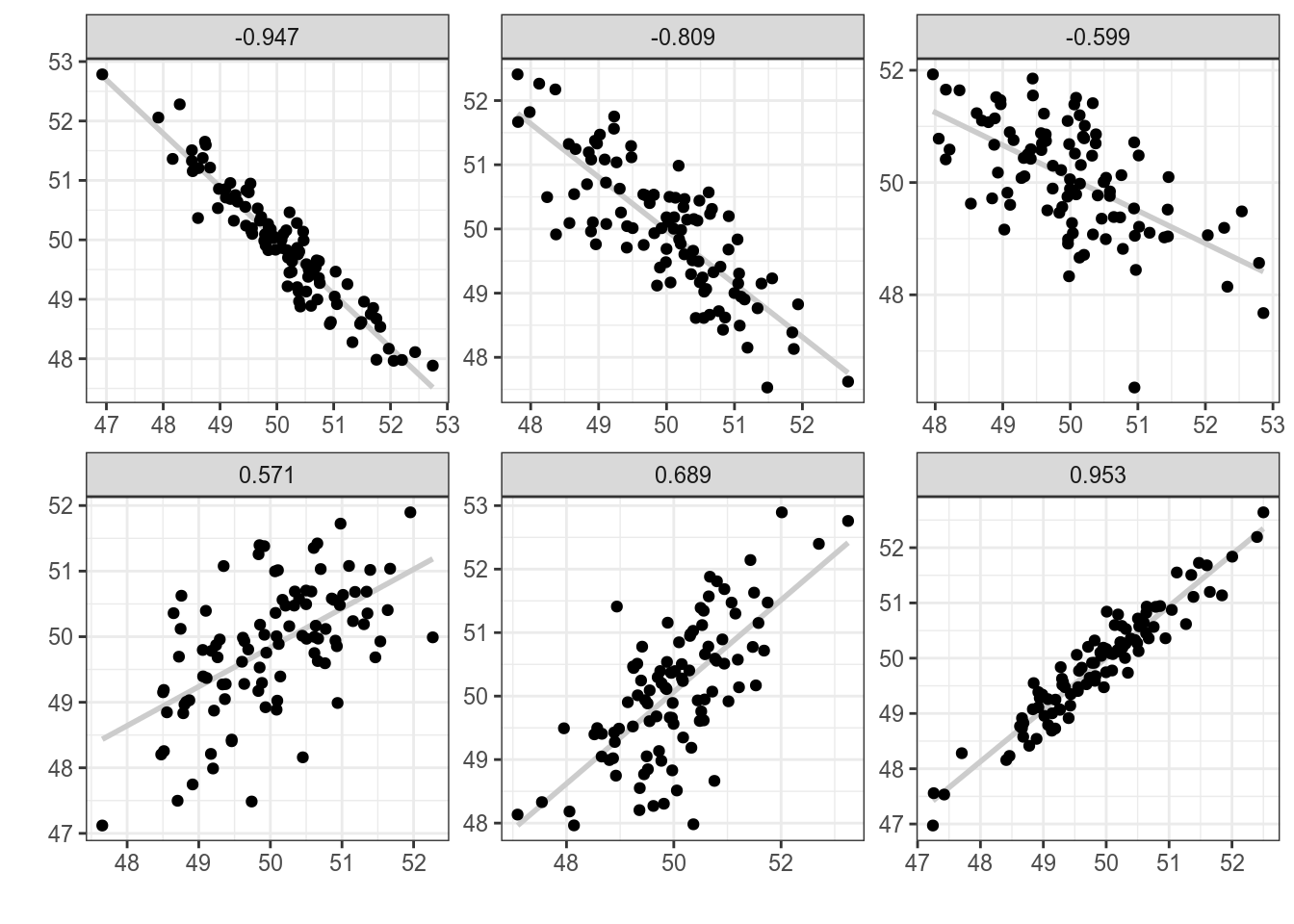
Эта нормализация приводит к тому, что Для того чтобы было понятнее, что такое корреляция, давайте рассмотрим несколько расспределений с разными значениями корреляции:
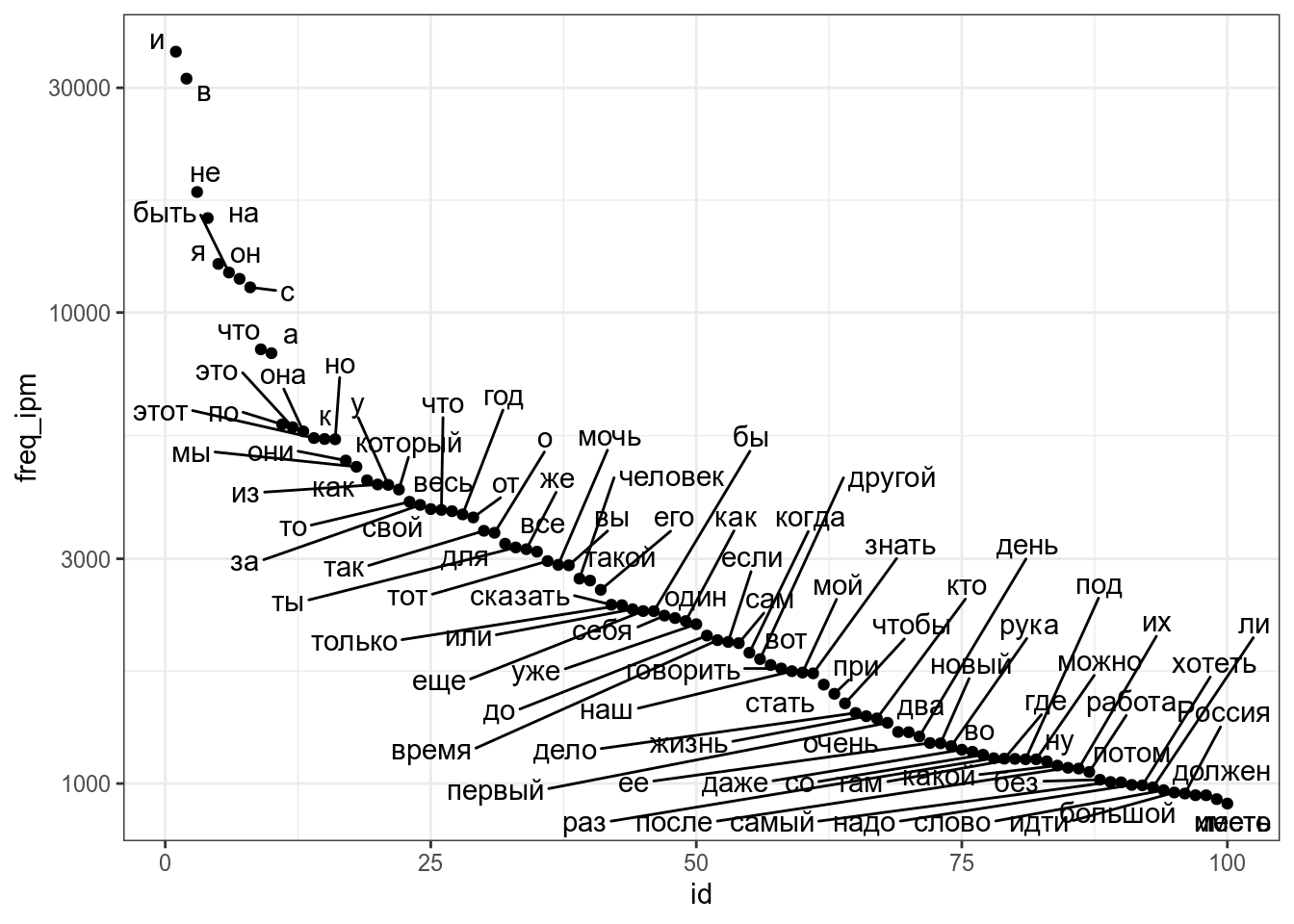
Как видно из этого графика, чем ближе модуль корреляции к 1, тем боллее компактно расположены точки друг к другу, чем ближе к 0, тем более рассеяны значения. Достаточно легко научиться приблизительно оценивать коэфициент корреляции на глаз, поиграв 2–5 минут в игру “Угадай корреляцию” здесь или здесь. Проверим, что функция выдает то же, что мы записали в формуле. Посчитайте на основе датасета с температурой корреляцию между разными измерениями в шкалах Фарингейта и Цельсия? Результаты округлите до трех знаков после запятой. 15.4.2 Ранговые корреляции Спирмана и КендаллаКоэффициент корреляции Пирсона к сожалению, чувствителен к значениям наблюдений. Если связь между переменными нелинейна, то оценка будет получаться смещенной. Рассмотрим, например, словарь [Ляшевской, Шарова 2011]:
В целом корреляция между рангом и частотой должна быть высокая, однако связь между этими переменными нелинейна, так что коэффициент корреляции Пирсона не такой уж и высокий: Для решения той проблемы обычно используют ранговые коэффециенты коррляции Спирмана и Кендала, которые принимают во внимание ранг значения, а не его непосредственное значение. Давайте сравним с предыдущими наблюдениями и их логаотфмамиы: Корреляции для начинающихАпдейт для тех, кто сочтет статью полезной и занесет в избранное. Есть приличный шанс, что пост уйдет в минуса, и я буду вынужден унести его в черновики. Сохраняйте копию! Краткий и несложный материал для неспециалистов, рассказывающий в наглядной форме о различных методах поиска регрессионных зависимостей. Это все и близко не академично, зато надеюсь что понятно. Прокатит как мини-методичка по обработке данных для студентов естественнонаучных специальностей, которые математику знают плохо ВведениеЗачем это вообще надо? В науке и около нее очень часто возникает задача предсказания какого-то неизвестного параметра объекта исходя из известных параметров этого объекта (предикторов) и большого набора похожих объектов, так называемой учебной выборки. Пример. Вот мы выбираем на базаре яблоко. Его можно описать такими предикторами: красность, вес, количество червяков. Но как потребителей нас интересует вкус, измеренный в попугаях по пятибалльной шкале. Из жизненного опыта нам известно, что вкус с приличной точностью равен 5*красность+2*вес-7*количество червяков. Вот про поиск такого рода зависимостей мы и побеседуем. Чтобы обучение пошло легче, попробуем предсказать вес девушки исходя из ее 90/60/90 и роста. Исходные данныеВ качестве объекта исследования возьму данные о параметрах фигуры девушек месяца Плейбоя. Источник — www.wired.com/special_multimedia/2009/st_infoporn_1702, слегка облагородил и перевел из дюймов в сантиметры. Вспоминается анекдот про то, что 34 дюйма — это как два семнадцатидюймовых монитора. Также отделил записи с неполной информацией. При работе с реальными объектами их можно использовать, но сейчас они нам только мешают. Зато их можно использовать для проверки адекватности полученных результатов. Все данные у нас непрерывные, то есть грубо говоря типа float. Они приведены к целым числам только чтобы не загромождать экран. Есть способы работы и с дискретными данными — в нашем примере это например может быть цвет кожи или национальность, которые принимают одно из фиксированного набора значений. Это больше имеет отношение к методам классификации и принятия решений, что тянет еще на один мануал. Data.xls В файле два листа. На первом собственно данные, на втором — отсеянные неполные данные и набор для проверки нашей модели. ОбозначенияW — вес реальный Как оценить качество модели?Задача нашего упражнения — получить некую модель, которая описывает какой-либо объект. Способ получения и принцип работы конкретной модели нас пока не волнует. Это просто функция f(S, T, B, L), которая выдает вес девушки. Как понять, какая функция хорошая и качественная, а какая не очень? Для этого используется так называемая fitness function. Самая классическая и часто используемая — это сумма квадратов разницы предсказанного и реального значения. В нашем случае это будет сумма (W_p — W)^2 для всех точек. Собственно, отсюда и пошло название «метод наименьших квадратов». Критерий не лучший и не единственный, но вполне приемлемый как метод по умолчанию. Его особенность в том, что он чувствителен по отношению к выбросам и тем самым, считает такие модели менее качественными. Есть еще всякие методы наименьших модулей итд, но сейчас нам это пока не надо. Простая линейная регрессияСамый простой случай. У нас одна переменная-предиктор и одна зависимая переменная. В нашем случае это может быть например рост и вес. Нам надо построить уравнение W_p = a*L+b, т.е. найти коэффициенты a и b. Если мы проведем этот расчет для каждого образца, то W_p будет максимально совпадать с W для того же образца. То есть у нас для каждой девушки будет такое уравнение: Общая ошибка в таком случае составит sum(E_i). В результате, для оптимальных значений a и b sum(E_i) будет минимальным. Как же найти уравнение? МатлабГрафичек
Расчет в матричном видеМультилинейная регрессияПопытка номер два
W_p = 0.2271*S + 0.1851*T + 0.3125*B + 0.3949*L — 72.9132 Объемы в сантиметрах, вес в кг. Поскольку у нас все величины кроме роста в одних единицах измерения и примерно одного порядка по величине (кроме талии), то мы можем оценить их вклады в общий вес. Рассуждения примерно в таком духе: коэффициент при талии самый маленький, равно как и сами величины в сантиметрах. Значит, вклад этого параметра в вес минимален. У бюста и особенно у бедер он больше, т.е. сантиметр на талии дает меньшую прибавку к массе, чем на груди. А больше всего на вес влияет объем задницы. Впрочем, это знает любой интересующийся вопросом мужчина. То есть как минимум, наша модель реальной жизни не противоречит. Валидация моделиНазвание громкое, но попробуем получить хотя бы ориентировочные веса тех девушек, для которых есть полный набор размеров, но нет веса. Их 7: с мая по июнь 1956 года, июль 1957, март 1987, август 1988. Находим предсказанные по модели веса: W_p=X*repr ПрименимостьЕсли вкратце — полученная модель годится для объектов, подобных нашему набору данных. То есть по полученным корреляциям не стоит считать параметры фигур женщин с весом 80+, возрастом, сильно отличающимся от среднего по больнице итд. В реальных применениях можно считать, что модель пригодна, если параметры изучаемого объекта не слишком отличаются от средних значений этих же параметров для исходного набора данных. Могут возникнуть (и возникнут) проблемы, если у нас предикторы сильно коррелированы между собой. То есть, например это рост и длина ног. Тогда коэффициенты для соответствующих величин в уравнении регрессии будут определены с малой точностью. В таком случае надо выбросить один из параметров, или воспользоваться методом главных компонент для снижения количества предикторов. Если у нас малая выборка и/или много предикторов, то мы рискуем попасть в переопределенность модели. То есть если мы возьмем 604 параметра для нашей выборки (а в таблице всего 604 девушки), то сможем аналитически получить уравнение с 604+1 слагаемым, которое абсолютно точно опишет то, что мы в него забросили. Но предсказательная сила у него будет весьма невелика. Наконец, далеко не все объекты можно описать мультилинейной зависимостью. Бывают и логарифмические, и степенные, и всякие сложные. Их поиск — это уже совсем другой вопрос. Коэффициенты корреляции для данных, полученных в разных шкалах измеренийВ психологических исследованиях довольно часто разные переменные измеряются в разных шкалах. Поэтому для этих случаев в корреляционном анализе также есть свои специальные критерии, а именно рангово-бисеральный и бисеральный коэффициенты. Рангово-бисеральный коэффициент корреляции (Rrb) и условия его применения: – одна переменная представлена в дихотомической шкале, другая – в порядковой; – параметры нормальности распределения не учитываются; – переменные X и Y имеют одинаковое число наблюдений; – для определения уровня достоверности применяется формула для Тф, а для его оценки также следует обратиться к таблицам критических значений t-критерия Стьюдента (со степенями свободы n – 2). Бисеральный коэффициент корреляции (Rбис) и условия его использования: – переменная Х представлена в дихотомической шкале, переменная Y – в метрической (интервалов или отношений); – значения переменной Y должны описываться законом нормального распределения; – переменные X и Y имеют одинаковое число наблюдений; – для определения уровня достоверности применяется формула для Тф, а для его оценки также следует обратиться к таблицам критических значений t-критерия Стьюдента (со степенями свободы n – 2). Показатель этих коэффициентов корреляции также имеет значения от –1 до +1, однако при интерпретации полученных с их помощью результатов этот знак не учитывается. В заключение следует отметить, что возможности корреляционного анализа не исчерпываются вышеописанными. Существуют и более сложные варианты связей между переменными. Например, множественная корреляция (между тремя переменными X, Y и Z), частная корреляция (связь двух зависимых переменной с третьей), корреляционное отношение (выраженное двумя показателями, поскольку связь устанавливается с двух сторон, как с позиции X, так и позиции Y) и др. МЕТОДЫ МНОГОМЕРНОГО АНАЛИЗА 1. Дисперсионный анализ. 2. Факторный анализ. 3. Многомерное шкалирование. 4. Кластерный анализ. 6. Дискриминантный анализ. Дисперсионный анализ Дисперсионный анализ – метод, предложенный Р. Фишером (F-тест). Называется также ANOVA (Аnalysis of Variance – анализ вариативности). Представляет собой анализ изменчивости признака под влиянием каких-либо контролируемых факторов. Чем выше эмпирическое значение F, тем больше признак варьирует под воздействием интересующего исследователя фактора (или их взаимодействия). Дисперсионный анализ позволяет устанавливать только изменение признака, но не направление этих изменений. Прежде чем приступать к дисперсионному анализу, психолог должен содержательно обосновать, почему какие-либо переменные выступают причиной (это и есть факторы), а другие – следствиями (они называются результативными признаками). Условия применения дисперсионного анализа: – фактор может быть выражен в любой шкале (в том числе в номинативной: например, по признаку пола создаются две группы; по уровням мотивации – низкому, среднему, высокому – три группы и др.); – результативные признаки должны быть выражены в метрических шкалах, а их значения в выборке соответствовать нормальному распределению (при определенных условиях это требование можно и обойти); – выборки могут быть независимыми и зависимыми; – сравнивать возможно две и более выборок; – выборки могут быть любого объема (от 2 до ∞); – если выборки разного объема, то значимым выступает требование соблюдения равенства дисперсий. Дисперсионный анализ имеет различные виды, конкретный выбор которого зависит: – от числа контролируемых факторов, в соответствии с которыми выделяются однофакторный, двухфакторный, мультифакторный дисперсионный анализ; – количества уровней каждого из контролируемых факторов (двух-, трехуровневый и т.п. дисперсионный анализ); – числа исследуемых сочетаний факторов: если анализируются сочетания всех факторов на всех уровнях, то необходим полный дисперсионный анализ; если часть сочетаний опускается, тогда проводится дробный дисперсионный анализ. Аналогами однофакторного дисперсионного анализа выступают непараметрические критерии – Н критерий Крускала-Уоллиса (для независимых выборок) и критерий χ²r Фридмана (для зависимых выборок), позволяющие оценить различия измеренного признака в трех и более условиях. Однако названные непараметрические критерии предназначены только для выборок малого объема. Поэтому при увеличении выборки следует обратиться к однофакторному дисперсионному анализу. Дисперсионный анализ является единственным и незаменимым методом при решении задачи выявления одновременного воздействия двух и более факторов на интересующий признак (речь идет о двухфакторном и мультифакторном анализах). Иначе говоря, только благодаря дисперсионному анализу можно выявить взаимодействие нескольких факторов в их влиянии на один и тот же результативный признак. Факторный анализ Данный метод был специально разработан для решения психологических задач, а позднее оказался очень востребованным и другими науками. Идея его создания принадлежит Ф. Гальтону, высказавшему идею о наличии некоторого общего, скрытого фактора способностей, благодаря которому можно объяснить их индивидуальную изменчивость. В 30-е гг. ХХ в. эта идея была воплощена Ч. Спирменом в однофакторном анализе, итогом которого стала модель общего интеллекта. Позднее были разработаны многофакторные модели интеллекта (Ч. Терстоун) и личности (Р. Кеттелл). Психическая реальность является многомерной. Например, индивидуально-психологические особенности личности измеряются очень большим числом переменных, что значительно затрудняет их анализ и интерпретацию. Кроме того, переменные, как правило, каким-то образом взаимосвязаны друг с другом, за ними может стоять некоторый общий фактор/факторы. Поэтому возникает необходимость это исходное множество объединить, укрупнить для перехода на более высокий уровень обобщения и понимания изучаемых феноменов. Именно эту задачу позволяет решить факторный анализ. Факторный анализ – это метод выявления корреляционных отношений между переменными, позволяющий определить структуру взаимосвязи между ними и сократить их число. Иначе говоря, этот метод выступает еще как метод структурной классификации и метод сокращения (редукции) данных. Условия применения факторного анализа: – переменные могут быть измерены только в метрических шкалах; – переменные должны быть независимыми; – распределение измеренных признаков должно приближаться к нормальному; – оптимально, чтобы связи между переменными имели линейный характер и хотя бы несколько переменных коррелировали друг с другом на высоком уровне значимости; – рекомендуемый объем выборки равен 100 (при меньшем объеме появляются слишком большие стандартные ошибки корреляций). Спецификой факторного анализа выступает то, что обрабатываются не сами «сырые» данные, а корреляционные матрицы (или матрицы интеркорреляций). Существуют различные виды факторизации: метод главных компонент, центроидный, максимального правдоподобия и др. Вне зависимости от конкретной процедуры фактор выступает как некоторый искусственный математический показатель, появляющийся в результате преобразования матрицы корреляций. В один фактор объединяются переменные, максимально друг с другом взаимосвязанные, другой фактор включает другие переменные, также значимо коррелирующие друг с другом и т.п. Т.е., образно говоря, фактор представляет собой пучок взаимосвязанных друг с другом переменных. Количество выделяемых факторов определяется исследовательскими задачами и тем, что для психолога выступает неслучайным в общем контексте всей научной работы (поэтому существует несколько правил отбора значимых факторов: критерий Кайзера, критерий «каменистой осыпи», процент объясненной дисперсии и др.). Результаты факторного анализа чаще всего представляются как перечисление образующих фактор шкал с указанием их факторной нагрузки. К примеру, в исследовании модели успешного современного человека в группе 50 взрослых людей (Е.И. Медведская, 2013) был выделен следующий фактор: понимать самого себя 0,985 отсеивать ненужную информацию 0,822 понимать язык тела 0,777 слушать другого человека 0,687 систематизировать знания 0,551 разбираться в других людях 0,490 хорошо одеваться 0,418 Как следует из представленного примера, факторный анализ дает взаимосвязь наиболее коррелирующих шкал (причем эта корреляция не всегда логична с точки зрения теории), а перед психологом стоит довольно сложная задача обобщения обнаруженных разнородных взаимосвязей и их интерпретации как непротиворечивого целого. |