Альтернативное использование мощностей GPU?
Недавно я опубликовал статью о распределенном рендеринге на GPU — поступили некоторые вопросы и предложения. Поэтому считаю нужным рассказать о теме более развернуто (и с картинками, а то без картинок статьи практически не читают), тем самым привлечь к этой теме больше читателей.
Думаю, этим вопросом заинтересуются обладатели мощных вычислительных систем: майнеры, геймеры, админы других мощных вычислительных систем.
Многие обладатели мощного железа задумывались над тем, а нельзя ли подзаработать на мощности своей железки, пока она стоит бестолку?

Красота моя бестоковая!
Один из самых доступных способов — это Bitcoin. В связи с появлением распределенной платежной системы Bitcoin появилось такое интересное занятие — майнинг («добыча биткоинов», вычисления в пользу защиты биткоин системы, за которые система вознаграждает участника биткоинами, которые он может обменять на одну из известных валют в биткоин биржах) — занятие достаточно затратное, и не всегда прибыльное. Вернее майнинг оказался более прибыльным на FPGA-шечках, чем на Радеончиках. Поэтому обладателям последних повезло меньше, в плане майнинга, и им приходится продавать свои железки.

Майнинг ферма, я насчитал 66 видеокарт. Красотища! Взято отсюда.
Я сам пробовал недавно помайнить на GTX580 (а Нвидии плохи для майнинга, да), но понял, что 17 (семнадцать) долл. в месяц — хоть и бешеные деньги, но не совсем та зарплата, о которой я мечтал.
Но не спешим впадать в спячку отчаяния! Можно попытаться спасти положение!
Итак, мощные видюшки, при правильном использовании:
1. Могут служить во благо кому-то.
2. Могут приносить больше прибыли, чем Биткоин.
3. Приносить прибыль от Биткоин во время простоя.
В чем же могут пригодиться видеокарты?
1. Вычисления общего назначения на видеокартах (англ. General Purpose Graphic Processor Unit — GPGPU).
2. Аппаратная растеризация (OpenGL, DirectX).
Начнем с GPGPU
Как задействовать видеокарты?
CUDA — хороший френймворк для карточек Nvidia, и только для них. Аппаратно-зависимая платформа.
Firestream — фреймворк для GPGPU вычислений на видеокартах AMD. Опять-таки аппаратно-зависимая платформа. Честно, я даже не встречал ни одного рендера на Firestream.
OpenCL — аппаратно, и программно-независимая платформа для вычислений на чем попало: и CPU, и GPU, на тостерах и микроволновках. Всё прекрасно, но на личном опыте, и многочисленных тестах убедился, что платформа пока что далека от совершенства. Глюки, баги, плохая оптимизация. Может пишут на нем кривыми ручками? Не знаю, может кто-то в комментариях выскажет.
HLSL — шейдерный язык DirecrX. Что такое шейдерный? На нем пишут алгоритмы закрашивания поверхностей в DirectX. Даже один товарищ сделал рендер на HLSL. Всё бы ничего, но платформа программно-зависимая. Только DirectX от Мелкомягких.
DirectCompute — прикладной (к DirectX, к чему еще) язык программирования от Мелкомягких. Частенько, с помощью него на видеокарты вешают физику.
GLSL — шейдерный язык OpenGL. А OpenGL, как мы знаем, поддерживает подавляющее большинство железок, работает на Windows, Linux, OSX. Так что вариант вроде бы самый выигрышный. Честно, серьезного софта я на нем не видел, но думаю, есть повод задуматься. Попробовать, а не искать оправдания, почему его не используют.
В негра-фических вычислениях GLSL пользуется популярностью в WebGL приложениях. Можете сами посмотреть как работает unbiased render на WebGL, и мышкой помешать пиксели на экране.
Есть ролик, показывающий производительность кода, написанного с помощью разных фреймворков на Nvidia GeForce GTS250 и Core i5.
Это видео — не абсолютный показатель. Во-первых инфа могла устареть, а вдруг, OpenCL уже быстрее всех на свете? Во-вторых, GTS250 — это же не топовая видеокарта, чтобы оценивать производительность OpenCL на тех же майнинг фермах.
На мой взгляд, наиболее подходящие платформы:
1. GLSL в виду его универсальности, стабильности и скорости. Минус — неудобство программирования.
2. OpenCL — универсален, всеяден. Задействует все поддерживаемые CPU и GPU. Минус — есть недоработки.
3. Совмещать 1 и 2.
Задач, которые нуждаются в вычислениях на GPU великое множество. Инженерных, научных, финансовых, графических. Я же сконцентрируюсь на рендеринге (о котором я расскажу чуть дальше), так как занимаюсь графикой, и мне есть что сказать на этот счет.
Аппаратная Растеризация
Первое, что приходит в голову — облачные игры (см. Onlive). Облачная отрисовка игр — это когда требовательная к ресурсам игра рисуется удаленно, на вычислительном сервере, а готовая картинка со звуком присылается пользователю. Пользуются этим, если компьютер пользователя едва тянет эту же игру на самых низких настройках, или вообще несовместим с этой игрой.
Ролик о том, как на Android планшете можно играть требовательные к железу игры:
Итак, теперь вернемся к системе облачно-распределенного рендеринга, которую я хочу предложить.
ОБЛАЧНЫЙ РЕНДЕРИНГ
Алгоритм хорош тем, что позволяет рендерить глобальное освещение (свет, отражения света, отражения отражений, отражения отражений отражений, и т.д.) в реальном времени, пусть и с большим шумом.
Но чем больше производительность железки — тем быстрее изображение прочищается от шума.
Но не бросать же в беде обладателей Радеонов! Есть рендеры, задействующие OpenCL:
Это Cycles Render (opensource), IndigoRT, SmallLuxGPU (тоже opensource)
Вообще, думаю, время покажет, что лучше: писать свой софт, или разбираться в чужом коде.
В каком виде подавать?
1. Через плагин 3d редактора.
2. Через браузер с жаваскриптом. Кстати, можно сделать что-то вроде «кинул ссылочку — показал кому-то 3д объект».
А как использовать эту систему: за деньги, или даром для друзей или ради интересного проекта — пользователи решат сами.
Может и задачи на CPU распределим?
Как мы знаем, графические видеоадаптеры обладают достаточно высокой (по сравнению с CPU) производительностью в многопоточных вычислениях. Но вовсе не обязательно списывать CPU со счетов. Есть задачи, которые очень сложны в написании, или нецелесообразны в использовании GPU.
Хотя, в целом, мое мнение отражает вот эта картинка: 
Ну а пост без баяна — не пост.
Идеологическая составляющая проекта
 Вычисления — лишь часть ресурсов, которые нуждаются в перераспределении. Одни нуждаются в производительном железе, у других оно стоит незадействованное. То же самое касается и других ресурсов: деньги, вода, пища, энергия, тепло. У одних избыток, не приносящий радости — у других недостаток, доставляющий дискомфорт.
Вычисления — лишь часть ресурсов, которые нуждаются в перераспределении. Одни нуждаются в производительном железе, у других оно стоит незадействованное. То же самое касается и других ресурсов: деньги, вода, пища, энергия, тепло. У одних избыток, не приносящий радости — у других недостаток, доставляющий дискомфорт.
Человечество нуждается в взаимопомощи во всех аспектах жизни. А рендеринг и распределенные вычисления — лишь малая часть ресурсов, которыми мы можем помочь друг другу. Все-таки целесообразнее задействовать существующие простаивающие мощности, чем покупать новые железки?
Это я к тому, что за распределенными вычислениями будущее! Я вовсе не утверждаю, что проект должен развиваться на голом энтузиазме, а разработчики — питаться святым духом.
Почему видеокарта и процессор не могут заменить друг друга.
Не так давно на сайте был материал в котором мы смотрели на то как процессор сам ядрами отрисовывает игры. При этом процессор потреблял огромное количество энергии, выдавая почти ничего. В тоже время даже встроенная графика в этот процессор потребляя полтора десятка ватт смогла бы выдать производительности раз в пять больше.
Исходя из этого возникает вопрос — «почему так происходит и почему есть и процессор и видеокарта?». Ведь по данному материалу может показаться, что видеокарта не слабо так мощнее процессора. И встаёт вопрос — зачем тогда нужен процессор.
Поэтому предлагаю разобраться в чём причина наличия обоих вычислителей в компьютере и ещё ещё рассмотрим историю одного проекта intel, который как раз был направлен на сочетание всех положительных сторон этих вычислителей и уменьшении отрицательных.
С устройством ядер процессора я уже вас знакомил в некоторых прошлых материалах, есть статья и про архитектуру современных Intel процессоров и про AMD, но основные моменты напомню ещё раз.
Между Intel и AMD местами есть довольно большая разница, но если разделить работу на 4-5 этапов, то есть максимально обобщить суть работы — то в целом — суть у них одна и та же. И для удобства остановимся на схеме из статьи про Intel.
 Нажмите для увеличения
Нажмите для увеличения
Условно можно сказать что есть некоторая центральная часть — это исполнительные блоки, в которых и происходит вычисление. И к этой основной части должно прийти две важные вещи. Первая это — «что делать», а вторая — «с чем делать». Чтобы это всё было поставлено в исполнительные блоки точно вовремя есть очереди и регистры в которых эти очереди реализованы. И все эти сложности направлены на то, чтобы каждый такт процессора подобрать такие комбинации различных задач чтобы занять наибольшее количество исполнительных блоков.

То есть не так сложно выполнить вычисления, сложно сделать так, чтобы различные задачи можно было выполнить без лишних простоев, связанных с постоянным изменением задачи. Именно поэтому растут и объёмы кеша, да и размеры регистров очередей, чтобы как можно больше поблизости с ядрами хранить «что делать» и «с чем делать», и также хранить что было сделано ранее, чтобы временами на основе этого делать что-то похожее в будущем, затрачивая меньше ресурсов, или делать что-то, когда новых ресурсов ещё нет, проверяя правильность выполнения работы уже постфактум, когда ресурсы появятся в доступе.
Дополнительная большая проблема заключается в том, что современные процессоры наследуют совместимость с довольно старыми решениями. Архитектуре x86 уже не мало лет и в процессе её развития в определенный момент она так сильно усложнилась, что сделать адекватные по составу, и требованиям к количеству транзисторов исполнительные блоки, стало сложно. И с переходом на Pentium III классическая CISC архитектура предполагающая высокую гибкость по возможным командам стала уже мешать дальнейшему развитию процессоров. И Intel пошли на смелый шаг — сделать внутри процессора — аппаратно-программный комплекс по переводу в режиме реального времени разнообразных CISC команд в более узкие по возможностям команды, но с которыми было бы легче работать и выстраивать из них очереди и выполнять. AMD пошли по тому же пути.
То есть возникла матрёшка имеющая внешнюю оболочку, внутри которой уже настоящее ядро.

Но все внешние общения процессора производятся так, как буд-то внутренней части нет. И это создаёт немало сложностей из-за которых внутренние адресации процессора не совпадают с внешними, возникает и ещё куча проблем связанных с тем, что внутри ядра происходит очень сильное переопределение порядка как выполнения самих операций изначальных, так и частей уже разбитых на микрооперации внутренних решаемых ядром задач. Но на выходе процессор должен собрать всю очередь обратно так как буд-то ничего не перемешивалось.
И все эти сложности направлены на то чтобы обеспечить индивидуальный подход к каждой задачи и получить максимальную производительность.
Как вы понимаете — при отрисовки игр — мы имеем дело с кучей однотипных задач. Но процессор по другому решать задачи не умеет, и с индивидуальным подходом массовые задачи решать сложно. Вернее процессоры массово выполнять что-то умеют, но не всегда. Существуют специальные инструкции, которые собирают ряд однотипных задач над неким набором данных для совместного выполнения.
 Расширение поддерживаемых инструкций
Расширение поддерживаемых инструкций
Например AVX инструкции. Благодаря этому компонованию — внешний слой матрёшки надо проходить не для каждого действия отдельно — а блоком целиком. Что уже сильно ускоряет весь процесс по решению задачи, кроме того — процессор знает, что некоторые используемые данные и операции будут применяться в ближайшее время по несколько раз, что упрощает очереди и меньше надо туда-сюда между регистрами лишний раз перебрасывать информацию. Но всё равно — производительность будет ограничиваться числом портов на исполнительные блоки у Intel и числом исполнительных блоков у AMD в самом радужном раскладе, который на практике недостижим.
В видеокартах же всё происходит совсем иначе.
Во первых — современный вариант видеокарт, в которых появились вычислительные блоки, общего назначения — появился гораздо позже архитектуры x86, и сложность в выполнении широкого круга разных операций уже была понятна, так что делать CISC ядра никто и не думал. И никакие обратные совместимости не требовали делать какие-то мартёшочные костыли. Поэтому процессоры в видеокартах умеют работать с малым числом инструкций, но зато работать с ними они могут непосредственно не переделывая, и от этого — эффективно.
Из этого сразу можно сделать вывод, что заменить процессор для привычных нам сред работы видеокарты не могут просто в силу архитектурных ограничений, они просто не могут работать с тем разнообразием задач и команд без предварительной трансляции их в понятный для видеокарт вид.
Ну и собственно процесс работы с видеокартами вообще бывает разный. И как раз чтобы работа с видеокартами была максимально без посредников существуют API на которых работают игры и прочие средства для разработчиков, которые позволяют работать с аппаратными ресурсами видеокарт непосредственно для какого-то прикладного софта.
Но это только половина дела. Особенность задач для видеокарт заключается в том, что им надо повторить одни и те же действия для кучи данных. То есть задача совершенно иная, в отличие от центрального процессора, который должен максимально оперативно подстраиваться под разные задачи.
Соответственно и архитектурные особенности видеокарт были созданы так, чтобы именно такие задачи и решать.
В процессорах планировщик, который ведает всеми очередями и решает когда и кто из них выйдет — занимается очень сложной задачей, потому что всё разное и надо это всё разное как-то скомпоновать в разные исполнительные блоки.
В видеокартах тоже есть планировщики, но задачи у них проще. Надо взять кучу чего-то однотипного и раскидать это по всему что есть. Именно поэтому в процессорах планировщик ведает малым числом исполнительных устройств. В видеокартах — каждый планировщик отвечает за целые большие кластеры исполнительных устройств, которые называют ядрами видеокарт или потоковыми процессорами видеокарт.

И то, количество задач, которое центральному процессору потребовалось бы распределять на доступные ему вычислительные средства на несколько тактов работы, в видеокартах планировщики делают за один такт. То есть передают команды целой армии исполнителей, которые тоже максимально упрощены под узкий круг решаемых задач.
При этом для видеокарт однотипных задач так много, что там решая целые кучи вычислений — всё равно эти задачи разбиваются на много тактов, смены задач происходят редко, так что и хранить что-то не так важно, и удельный объём кешей на каждый исполнительный блок на порядки меньше, чем у центральных процессоров. В общем — вся обвязка и всё обеспечение инструкциями и данными для видеокарт сильно проще, чем у центральных процессоров, и занимает куда меньше места. А значит — на равную площадь можно запихать очень много вычислительных блоков.
Однако стоит отметить, что архитектуры видеокарт для универсальных вычислений появились тоже уже довольно давно. Так что концепция — объединения вычислительных потоков под простые планировщики, которые почти ничего не должны уметь — устаревает.
Вычислительный потенциал карт не даёт покоя никому, ни игроделам, ни другим программистам работающим над каким-то прикладным софтом. Поэтому всё более сложные работы начинают передавать для вычислений видеокартами. Естественно это отражается и в эволюции API и SDK для работы с ресурсами видеокарт, но так же это требует и модернизации самой концепции видеокарт.
И карты от AMD и от Nvidia, с горем пополам, если сравнивать с центральными процессорами, уже могут выдавать разные задачи на разные блоки видеокарты, а не так чтобы у всех одно и тоже, а если нужно что-то другое, то надо ждать следующих тактов.
То есть видеокарты идут в сторону усложнения, что, скорее всего лишит их по меньшей мере энергоэффективности. Будет падать и удельная площадь кристалла занятого ядрами (на схеме выше вы можете увидеть, что на Тюринге уже стоит планировщик на каждые 16 ядер, а не 32, как было ранее), то есть будет больше транзисторного бюджета уходить на обвязку ядер и оставаться меньше места для того чтобы разместить больше ядер.
Итого подведем итоги и ответим на вопрос о том: почему есть и процессор и видекарта. Ответ — вполне прост. Видеокарта хороша тогда, когда есть очень много однотипных задач, она энергоэффективна, она имеет высокую вычислительную производительность, но видеокарты не могут эффективно работать в условиях постоянного изменения задач и лишены тех костылей, идущих из прошлого, для обеспечения совместимости со стандартами, которые стали неотъемлемыми для персональных компьютеров.
Центральный процессор может адаптироваться к постоянно меняющимся задачам, имеет много удельного кеша на ядро, и может выполнять более широкий спектр инструкций, но имеет очень большую обвязку для ядер, так что много ядер делать дорого, и из-за костылей имеет низкую энергоэффективность, которая также ограничивает возможности процессоров.
Но и тот и другой тип вычислителей сейчас идут друг к другу на встречу. Центральные процессоры уже могут в одну 512 битную инструкцию запихивать больше десятка операций, выполняя их максимально приближенно к единому блоку, видеокарты, в свою очередь, учатся выполнять одновременно разнородные задачи без значительных простоев потоковых процессоров.
Можно предположить, что должно появиться такое решение, которое будет гибридом этих двух вариантов. То есть будет гибким при выполнении разнородных задач, но при этом иметь много потоков и хорошо справляться с управлением этими потоками.
И попытка сделать такое устройство уже была сделана, но, к счастью или сожалению — устройство оказалось не столь удачным как хотелось бы.
Intel с середины 00-х до середины 10-х годов уже почти выпустили новый для себя и вообще для всего мира продукт Larrabee.

Это не должно было заменить центральный процессор, но и не должно было стать и просто видеокартой. Суть в том что Intel хотели объединить порядка 50 слабых процессоров, в единый вычислительный кластер.
Оно должно было сохранить x86 совместимую архитектуру, собственные планировщики и много кеша, но при этом ядра не умели бы переупорядочивать выполнение микроопераций и просто должны были рассчитывать на большой кеш для уменьшения простоев в работе. Но зато они бы были намного меньше по площади.

Кроме того в ядра должны были быть добавлены специальные вычислительные блоки для работы с текстурами. То есть оно могло бы работать и как видеокарта. Ещё в этих гибридных процессорах должна была быть очень широкая шина связи ядер, а аналог HT выдавать не 2 потока на ядро, а 4, что с одной стороны увеличило бы сумятицу, без переопределений очередей и потребовало бы больший кеш, с другой стороны — в части задач могло бы увеличить пиковую производительность на такт за счёт более плотного задействования исполнительных блоков.

В конечном итоге данный проект как нечто напоминающее видеокарту не появились, часть всяких лишних для вычислителя возможностей было вырезано и всё это превратилось в процессоры Xeon Phi, а появившиеся впервые предпосылки к 512 битным инструкциям, которые могут вместить в себя до 16 операций с плавающей точкой уже дошли и до обычной архитектуры intel Тигер лейк.

В общим — отдельные фрагменты этих гибридов оказались жизнеспособными и успешно внедряются в различные решения от intel.
Но скорее всего соединяя процессор и видекоарту вместе, достоинства обоих методов видно будет не так хорошо, как суммирующиеся недостатки обоих методов.
Именно поэтому существует по отдельности процессор и видеокарта и друг друга они заменить, по крайней мере сейчас — не могут.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Суперкомпьютер из видеокарты: задействуем возможности GPU для ускорения софта
Сегодня новости об использовании графических процессоров для общих вычислений можно услышать на каждом углу. Такие слова, как CUDA, Stream и OpenCL, за каких-то два года стали чуть ли не самыми цитируемыми в айтишном интернете. Однако, что значат эти слова, и что несут стоящие за ними технологии, известно далеко не каждому. А для линуксоидов, привыкших «быть в пролете», так и вообще все это видится темным лесом.
Предисловие
В этой статье мы попытаемся разобраться, зачем нужна технология GPGPU (General-purpose graphics processing units, Графический процессор общего назначения) и все связанные с ней реализации от конкретных производителей. Узнаем, почему эта технология имеет очень узкую сферу применения, в которую подавляющее большинство софта не попадает в принципе, и конечно же, попытаемся извлечь из всего этого выгоду в виде существенных приростов производительности в таких задачах, как шифрование, подбор паролей, работа с мультимедиа и архивирование.
Рождение GPGPU
Мы все привыкли думать, что единственным компонентом компа, способным выполнять любой код, который ему прикажут, является центральный процессор. Долгое время почти все массовые ПК оснащались единственным процессором, который занимался всеми мыслимыми расчетами, включая код операционной системы, всего нашего софта и вирусов.
Позже появились многоядерные процессоры и многопроцессорные системы, в которых таких компонентов было несколько. Это позволило машинам выполнять несколько задач одновременно, а общая (теоретическая) производительность системы поднялась ровно во столько раз, сколько ядер было установлено в машине. Однако оказалось, что производить и конструировать многоядерные процессоры слишком сложно и дорого. В каждом ядре приходилось размещать полноценный процессор сложной и запутанной x86-архитектуры, со своим (довольно объемным) кэшем, конвейером инструкций, блоками SSE, множеством блоков, выполняющих оптимизации и т.д. и т.п. Поэтому процесс наращивания количества ядер существенно затормозился, и белые университетские халаты, которым два или четыре ядра было явно мало, нашли способ задействовать для своих научных расчетов другие вычислительные мощности, которых было в достатке на видеокарте (в результате даже появился инструмент BrookGPU, эмулирующий дополнительный процессор с помощью вызовов функций DirectX и OpenGL).
Графические процессоры, лишенные многих недостатков центрального процессора, оказались отличной и очень быстрой счетной машинкой, и совсем скоро к наработкам ученых умов начали присматриваться сами производители GPU (а nVidia так и вообще наняла большинство исследователей на работу). В результате появилась технология nVidia CUDA, определяющая интерфейс, с помощью которого стало возможным перенести вычисление сложных алгоритмов на плечи GPU без каких-либо костылей. Позже за ней последовала ATi (AMD) с собственным вариантом технологии под названием Close to Metal (ныне Stream), а совсем скоро появилась ставшая стандартом версия от Apple, получившая имя OpenCL.
GPU — наше все?
Несмотря на все преимущества, техника GPGPU имеет несколько проблем. Первая из них заключается в очень узкой сфере применения. GPU шагнули далеко вперед центрального процессора в плане наращивания вычислительной мощности и общего количества ядер (видеокарты несут на себе вычислительный блок, состоящий из более чем сотни ядер), однако такая высокая плотность достигается за счет максимального упрощения дизайна самого чипа.
В сущности основная задача GPU сводится к математическим расчетам с помощью простых алгоритмов, получающих на вход не очень большие объемы предсказуемых данных. По этой причине ядра GPU имеют очень простой дизайн, мизерные объемы кэша и скромный набор инструкций, что в конечном счете и выливается в дешевизну их производства и возможность очень плотного размещения на чипе. GPU похожи на китайскую фабрику с тысячами рабочих. Какие-то простые вещи они делают достаточно хорошо (а главное — быстро и дешево), но если доверить им сборку самолета, то в результате получится максимум дельтаплан. Поэтому первое ограничение GPU — это ориентированность на быстрые математические расчеты, что ограничивает сферу применения графических процессоров помощью в работе мультимедийных приложений, а также любых программ, занимающихся сложной обработкой данных (например, архиваторов или систем шифрования, а также софтин, занимающихся флуоресцентной микроскопией, молекулярной динамикой, электростатикой и другими, малоинтересными для линуксоидов вещами).
Вторая проблема GPGPU в том, что адаптировать для выполнения на GPU можно далеко не каждый алгоритм. Отдельно взятые ядра графического процессора довольно медлительны, и их мощь проявляется только при работе сообща. А это значит, что алгоритм будет настолько эффективным, насколько эффективно его сможет распараллелить программист. В большинстве случаев с такой работой может справиться только хороший математик, которых среди разработчиков софта совсем немного.
И третье: графические процессоры работают с памятью, установленной на самой видеокарте, так что при каждом задействовании GPU будет происходить две дополнительных операции копирования: входные данные из оперативной памяти самого приложения и выходные данные из GRAM обратно в память приложения. Нетрудно догадаться, что это может свести на нет весь выигрыш во времени работы приложения (как и происходит в случае с инструментом FlacCL, который мы рассмотрим позже).
Но и это еще не все. Несмотря на существование общепризнанного стандарта в лице OpenCL, многие программисты до сих пор предпочитают использовать привязанные к производителю реализации техники GPGPU. Особенно популярной оказалась CUDA, которая хоть и дает более гибкий интерфейс программирования (кстати, OpenCL в драйверах nVidia реализован поверх CUDA), но намертво привязывает приложение к видеокартам одного производителя.
KGPU или ядро Linux, ускоренное GPU
Исследователи из университета Юты разработали систему KGPU, позволяющую выполнять некоторые функции ядра Linux на графическом процессоре с помощью фреймворка CUDA. Для выполнения этой задачи используется модифицированное ядро Linux и специальный демон, который работает в пространстве пользователя, слушает запросы ядра и передает их драйверу видеокарты с помощью библиотеки CUDA. Интересно, что несмотря на существенный оверхед, который создает такая архитектура, авторам KGPU удалось создать реализацию алгоритма AES, который поднимает скорость шифрования файловой системы eCryptfs в 6 раз.
Что есть сейчас?
В силу своей молодости, а также благодаря описанным выше проблемам, GPGPU так и не стала по-настоящему распространенной технологией, однако полезный софт, использующий ее возможности, существует (хоть и в мизерном количестве). Одними из первых появились крэкеры различных хэшей, алгоритмы работы которых очень легко распараллелить. Также родились мультимедийные приложения, например, кодировщик FlacCL, позволяющий перекодировать звуковую дорожку в формат FLAC. Поддержкой GPGPU обзавелись и некоторые уже существовавшие ранее приложения, самым заметным из которых стал ImageMagick, который теперь умеет перекладывать часть своей работы на графический процессор с помощью OpenCL. Также есть проекты по переводу на CUDA/OpenCL (не любят юниксоиды ATi) архиваторов данных и других систем сжатия информации. Наиболее интересные из этих проектов мы рассмотрим в следующих разделах статьи, а пока попробуем разобраться с тем, что нам нужно для того, чтобы все это завелось и стабильно работало.
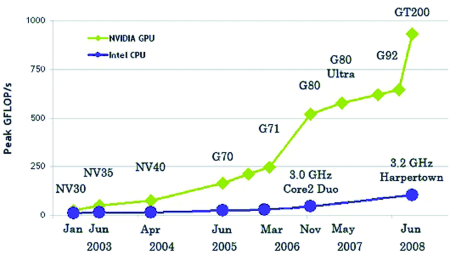
GPU уже давно обогнали x86-процессоры в производительности
Во-первых, понадобится видеокарта, поддерживающая технологию CUDA или Stream. Необязательно, чтобы она была топовая, достаточно только, чтобы год ее выпуска был не менее 2009. Полный список поддерживаемых видюшек можно посмотреть в Википедии: en.wikipedia.org/wiki/CUDA и en.wikipedia.org/wiki/AMD_Stream_Processor. Также о поддержке той или иной технологии можно узнать, прочитав документацию, хотя в большинстве случаев будет достаточным взглянуть на коробку из под видеокарты или ноутбука, обычно на нее наклеены различные рекламные стикеры.
Во-вторых, в систему должны быть установлены последние проприетарные драйвера для видеокарты, они обеспечат поддержку как родных для карточки технологий GPGPU, так и открытого OpenCL.
И в-третьих, так как пока дистрибутивостроители еще не начали распространять пакеты приложений с поддержкой GPGPU, нам придется собирать приложения самостоятельно, а для этого нужны официальные SDK от производителей: CUDA Toolkit или ATI Stream SDK. Они содержат в себе необходимые для сборки приложений заголовочные файлы и библиотеки.
Ставим CUDA Toolkit
Идем по вышеприведенной ссылке и скачиваем CUDA Toolkit для Linux (выбрать можно из нескольких версий, для дистрибутивов Fedora, RHEL, Ubuntu и SUSE, есть версии как для архитектуры x86, так и для x86_64). Кроме того, там же надо скачать комплекты драйверов для разработчиков (Developer Drivers for Linux, они идут первыми в списке).
Запускаем инсталлятор SDK:
$ sudo sh cudatoolkit_4.0.17_linux_64_ubuntu10.10.run
Когда установка будет завершена, приступаем к установке драйверов. Для этого завершаем работу X-сервера:
# sudo /etc/init.d/gdm stop
Открываем консоль и запускаем инсталлятор драйверов:
$ sudo sh devdriver_4.0_linux_64_270.41.19.run
После окончания установки стартуем иксы:
Чтобы приложения смогли работать с CUDA/OpenCL, прописываем путь до каталога с CUDA-библиотеками в переменную LD_LIBRARY_PATH:
Или, если ты установил 32-битную версию:
Также необходимо прописать путь до заголовочных файлов CUDA, чтобы компилятор их нашел на этапе сборки приложения:
Все, теперь можно приступить к сборке CUDA/OpenCL-софта.
Ставим ATI Stream SDK
Stream SDK не требует установки, поэтому скачанный с сайта AMD-архив можно просто распаковать в любой каталог (лучшим выбором будет /opt) и прописать путь до него во всю ту же переменную LD_LIBRARY_PATH:
Как и в случае с CUDA Toolkit, x86_64 необходимо заменить на x86 в 32-битных системах. Теперь переходим в корневой каталог и распаковываем архив icd-registration.tgz (это своего рода бесплатный лицензионный ключ):
Проверяем правильность установки/работы пакета с помощью инструмента clinfo:
ImageMagick и OpenCL
Поддержка OpenCL появилась в ImageMagick уже достаточно давно, однако по умолчанию она не активирована ни в одном дистрибутиве. Поэтому нам придется собрать IM самостоятельно из исходников. Ничего сложного в этом нет, все необходимое уже есть в SDK, поэтому сборка не потребует установки каких-то дополнительных библиотек от nVidia или AMD. Итак, скачиваем/распаковываем архив с исходниками:
Далее устанавливаем инструменты сборки:
$ sudo apt-get install build-essential
Запускаем конфигуратор и грепаем его вывод на предмет поддержки OpenCL:
Правильный результат работы команды должен выглядеть примерно так:
Словом «yes» должны быть отмечены либо первые три строки, либо вторые (или оба варианта сразу). Если это не так, значит, скорее всего, была неправильно инициализирована переменная C_INCLUDE_PATH. Если же словом «no» отмечена последняя строка, значит, дело в переменной LD_LIBRARY_PATH. Если все окей, запускаем процесс сборки/установки:
$ sudo make install clean
Проверяем, что ImageMagick действительно был скомпилирован с поддержкой OpenCL:
Теперь измерим полученный выигрыш в скорости. Разработчики ImageMagick рекомендуют использовать для этого фильтр convolve:
Некоторые другие операции, такие как ресайз, теперь тоже должны работать значительно быстрее, однако надеяться на то, что ImageMagick начнет обрабатывать графику с бешеной скоростью, не стоит. Пока еще очень малая часть пакета оптимизирована с помощью OpenCL.
FlacCL (Flacuda)
FlacCL — это кодировщик звуковых файлов в формат FLAC, задействующий в своей работе возможности OpenCL. Он входит в состав пакета CUETools для Windows, но благодаря mono может быть использован и в Linux. Для получения архива с кодировщиком выполняем следующую команду:
$ mkdir flaccl && cd flaccl
$ wget www.cuetools.net/install/flaccl03.rar
Далее устанавливаем unrar, mono и распаковываем архив:
$ sudo apt-get install unrar mono
$ unrar x fl accl03.rar
Чтобы программа смогла найти библиотеку OpenCL, делаем символическую ссылку:
Теперь запускаем кодировщик:
$ mono CUETools.FLACCL.cmd.exe music.wav
Если на экран будет выведено сообщение об ошибке «Error: Requested compile size is bigger than the required workgroup size of 32», значит, у нас в системе слишком слабенькая видеокарта, и количество задействованных ядер следует сократить до указанного числа с помощью флага ‘—group-size XX’, где XX — нужное количество ядер.
Сразу скажу, из-за долгого времени инициализации OpenCL заметный выигрыш можно получить только на достаточно длинных дорожках. Короткие звуковые файлы FlacCL обрабатывает почти с той же скоростью, что и его традиционная версия.
oclHashcat или брутфорс по-быстрому
Как я уже говорил, одними из первых поддержку GPGPU в свои продукты добавили разработчики различных крэкеров и систем брутфорса паролей. Для них новая технология стала настоящим святым граалем, который позволил с легкостью перенести от природы легко распараллеливаемый код на плечи быстрых GPU-процессоров. Поэтому неудивительно, что сейчас существуют десятки самых разных реализаций подобных программ. Но в этой статье я расскажу только об одной из них — oclHashcat.
oclHashcat — это ломалка, которая умеет подбирать пароли по их хэшу с экстремально высокой скоростью, задействуя при этом мощности GPU с помощью OpenCL. Если верить замерам, опубликованным на сайте проекта, скорость подбора MD5-паролей на nVidia GTX580 составляет до 15800 млн комбинаций в секунду, благодаря чему oclHashcat способен найти средний по сложности восьмисимвольный пароль за какие-то 9 минут.
И запустить программу (воспользуемся пробным списком хэшей и пробным словарем):
oclHashcat откроет текст пользовательского соглашения, с которым следует согласиться, набрав «YES». После этого начнется процесс перебора, прогресс которого можно узнать по нажатию . Чтобы приостановить процесс, кнопаем
И различные модификации словаря и метода прямого перебора, а также их комбинации (об этом можно прочитать в файле docs/examples.txt). В моем случае скорость перебора всего словаря составила 11 минут, тогда как прямой перебор (от aaaaaaaa до zzzzzzzz) длился около 40 минут. В среднем скорость работы GPU (чип RV710) составила 88,3 млн/с.
Выводы
Несмотря на множество самых разных ограничений и сложность разработки софта, GPGPU — будущее высокопроизводительных настольных компов. Но самое главное — использовать возможности этой технологии можно прямо сейчас, и это касается не только Windows-машин, но и Linux.