Распространенные примеры использования продвинутых JQL-запросов
В данной статье приведены наиболее часто используемые JQL-запросы с использованием различных функций. Данный материал удобно иметь под рукой при необходимости создания сложных JQL-запросов для проектов в JIRA. В первую очередь информация будет полезна менеджерам и тим-лидам. В данной статье собраны примеры запросов, которые наиболее часто используются мною в ежедневной проектной деятельности.
Важно: для некоторых запросов требуется установка плагина Adaptavist ScriptRunner
Типы связей (linkedIssuesOf и hasLinks)
Вывод всех issues, которые блокированы (имеют тип связи «blocked by») определенным issue (здесь сущность с ID TESTPROJECT-123) (способ требует установленного Adaptavist ScriptRunner).
Альтернативный способ, не требующий Adaptavist ScriptRunner:
Ссылка на другие фильтры
Вывод всех issues определенного фильтра:
Необходимо помнить, что если вы планируете использовать фильтры не только лично для себя, их необходимо «шарить» на нужных пользователей.
Вывести все подзадачи от сущностей, которые выводятся определенным фильтром
Функция membersOf (работа с группами)
Вывести все задачи в проекте TESTPROJECT, которые были созданы пользователем (указанным Reporter’ом), состоящим в группе «CompanyName»:
Работа с датами и временными интервалами
Вывести все, что создано до 1 февраля 2017 включительно:
Вывести все, что было обновлено с 16 июля 2017 по 22 июля 2017:
Вывести все задачи в проекте в которых изменялся статус с In-progress на resolved за последние 7 дней:
Для указания периодов так же можно использовать интуитивно понятные функции: startofweek(), endofweek(),startOfYear(), endOfYear()
Вывести все задачи, в которых изменялся статус с In-progress на resolved в период с 12 по 22 июля 2017:
Вывести все задачи, которые были в статусе In-progress в период с 12 по 22 июля 2017:
Вывести все задачи, по которым за текущую неделю менялся assignee на текущего пользователя:
Работа со релиз-версиями

Текущий релиз
Типы задач в Jira: основы, не зная которых рабочие процессы обречены на провал

Рассмотрим главную сущность Jira Software Atlassian — Issue. Она же тикет, таск и задача. Не все знают, что за этими названиями скрываются разные по своей сути сущности. Поэтому нужно понимать, к чему приводит выбор того или иного типа, что мы получим и как будем сущностью пользоваться. Если не учесть эту разницу, в работе начинается путаница и ведение проекта превращается в ад.
Каждый администратор Jira сталкивается с проблемой многоуровневой настройки интерфейса. Важно организовать все интуитивно понятно и сделать так, чтобы выбранная структура отражала взаимосвязь задач между собой. Тогда у вас будет четкое представление о продвижении работы в команде.
Типы Issue
Каждая составляющая работы в Jira, для который заводится отдельная карточка, называется Issue (в переводе «проблема» (англ.)). Это основное понятие, от которого идет дальнейшая настройка.
Все Issue разделены на две категории.
1. Standard Issue Type
2. Sub-task Issue Type
Внутри каждой категории проблем Jira Software Atlassian предлагает набор уже встроенных типов задач.
Standard Issue Type
Sub-task Issue Type
Чтобы не запутаться в терминологии, одну классификацию будем называть частными типами проблем (задач), другую глобальными.
 Структура Issue в Jira.
Структура Issue в Jira.
Глобальные типы проблем
Классификация всех задач определена принципами работы Jira. Если мы захотим создать новый тип Issue, увидим следующее окно.
 Добавление нового типа задач в Jira.
Добавление нового типа задач в Jira.
В Jira можно создать задачи только внутри двух глобальных категорий проблем — других не бывает.
Standard Issue Type и Sub-task Issue Type формируют базовую связку родительской и дочерней задачи. Если в начале работы выбрать не тот пункт, в дальнейшем мы не сможем выстроить корректную взаимосвязь между задачами.
Разделив проблемы на разные типы, мы можем не только отличить их друг от друга визуально, но и назначить им разные свойства, процессы, шаблоны описания и многое другое.
Standard Issue Type
Проблемы этого типа — автономные сущности:
Sub-task Issue Type
Проблемы этого типа — несамостоятельные сущности:
Проблемы категории Sub-task Issue Type включены в Jira по умолчанию. Если для выстраивания ваших процессов они не нужны, их можно отключить: настройки — Issue Types — Sub-tasks — Disable Sub-Tasks.
 Sub-task Issue Type в Jira.
Sub-task Issue Type в Jira.
Если убрать из спринта родительскую задачу «AREND-2203», вместе с ней уйдут все вложенные подзадачи Subtasks.
Частные типы проблем (задач)
Внутри каждой категории глобальных проблем Jira Software Atlassian предлагает набор уже встроенных частных проблем (типов задач) и возможность создавать собственные.
Задачами могут быть: задание по проекту, заявка в службу поддержки, требование пользователей, техническое задание на разработку, баг в ПО и т.д. Разные типы задач нужны именно для того, чтобы мы могли отделять эти виды работ друг от друга.
По умолчанию в Jira установлены следующие Issue Types:
Обратите внимание, что Sub-task относится к категории Sub-task Issue Type, а все остальные типы проблем к категории Standard Issue Type.
Принципиальные отличия задач типа Epic
Эпик относится к Standard Issue Type, но отличается от всех других типов задач этой категории:
Бывают, конечно, и исключения. Технически мы можем сделать один эпик родительским для другого. Можем сделать задачу категории Sub-task Issue Type внутри эпика. Так получится в том случае, если сначала мы создадим необходимую нам задачу категории Standard Issue Type, а потом изменим ее тип на «эпик».
Создание кастомных (частных) Issue Type
Если встроенных в Jira типов задач не хватает, можно создать сколько угодно собственных. Для этого нужно быть админом воркспейса.


При этом если в левом меню выбрать пункт Issue Types, увидим все типы задач, которые есть в нашем воркспейсе на данный момент. А выбрав меню Sub-tasks, увидим только подзадачи.
 Здесь отображаются все виды Issue Type вашего воркспейса.
Здесь отображаются все виды Issue Type вашего воркспейса.
Структура вложенности и организация деревьев задач
Для каких именно целей использовать различные типы Issue каждая команда решает самостоятельно. Это зависит от принятых ей особенностей выстраивания процессов. Однако техническое взаимодействие между различными Issue Type регламентирует Jira. Все задачи можно выстроить максимум в три ступени иерархии. Распределяться по уровням они могут ТОЛЬКО ТАК.
 Структура подчинения различных типов задач в Jira.
Структура подчинения различных типов задач в Jira.
Неужели, все это важно знать
Мы видим, как начинающие администраторы Jira создают слишком много кастомных типов задач. Видим, как они пытаются выдать одну задачу за другую, изменив только название и иконки задач. Так не работает.
Каждый тип Issue Type — это отдельная сущность. У нее есть назначение, определенные свойства и взаимосвязь с другими задачами. А еще разные типы задач мы используем для того, чтобы назначать каждому из них свой процесс. Иначе мы не увидим, как продвигается работа в команде.
В Jira, конечно, можно создать неограниченное количество кастомных типов задач. Но если их слишком много, это приводит лишь к путанице и не дает никакой наглядности. Лучше выделять не более 5-ти типов задач для одного проекта. Наличие каждого из них должно быть обоснованно и оправданно. Если у вас есть вопросы по Jira, напишите нам.
В следующей статье расскажем, как настраивать Workflow в Jira. Если правильно настроить воркфло, все этапы работы бизнеса становятся прозрачными и предсказуемыми 🙂
Подпишитесь на блог WB—Tech
Никакого спама, только анонсы новых статей!

Мария Михневич
Менеджер команды WB—Tech. Администратор таск-трекера Jira
Использование JIRA и Confluence в большом проекте
Начало нового проекта как правило сопровождается решением массы организационных вопросов: как будут взаимодействовать участники проекта, где будут храниться документы и как будет построено их согласование, как будут ставить задачи и выдавать поручения… В каждой компании, у каждого руководителя проектов, уже есть заготовки и предпочтения. Но всегда полезно посмотреть, как это делают другие. Поэтому предлагаю познакомиться с примером из практики, который вышел весьма удачным.
Для организации работы проектной команды необходим единый информационный центр, с помощью которого решаются следующие задачи:
Портал проекта — Confluence
Confluence — это удобный и продвинутый wiki движок от компании Atlassian. Он позволяет организовать внутренний интернет портал и дать доступ к нему всем пользователям — для редактирования или для чтения.
Проектный портал содержал все проектные материалы, часть которых мы сделали в виде иерархии страниц.
Верхний уровень иерархии — это этапы проекта. На каждом этапе создали страницы-ключевые задачи этапа. Причем на каждой странице — описание задачи, каково ее содержание, зачем она необходима, кто ее выполняет, приложены шаблоны документов.
Все контрактные документы, которые должны сдаваться в качестве результатов проекта, выкладывали на соответствующую страницу в Word, Excel или pdf. Таким образом все проектные материалы, были в одном месте, структурированы, и не было путаницы с версиями.
Масса полезной информации мы организовали в виде специальных страниц. Например, для большой команды крайне популярной является контактная карта, на которой у нас был список проектной команды по группам, с фотографиями и данными участников.
Страница со ссылками на экземпляры системы поддерживались системными администраторами. Там же была схема эволюции технической инфраструктуры — когда какие экземпляры появлялись и выводились из эксплуатации.
Процедуры и регламенты
Собрание всех инструкций и проектных регламентов на портале, в актуальном и удобном для чтения виде позволяет экономить на объяснениях новым участникам и бороться с отговорками «не прочитал, не нашел, не видел». Когда вопрос все-таки возникает, можно выслать ссылку на страничку, чтобы не пересылать документ и тратить время на его поиск. Версия — всегда актуальная, т.к. обновление происходит непосредственно на портале.
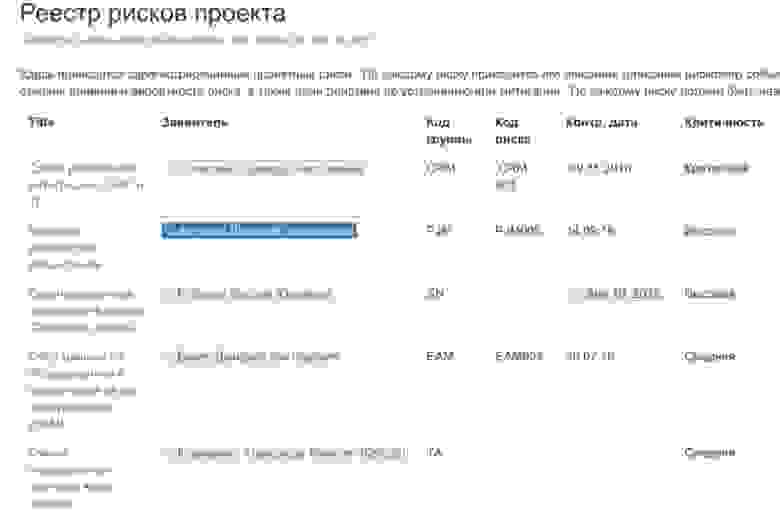
Риски и открытые вопросы
Мы вели на портале риски и открытые вопросы. На каждый риск или вопрос мы заводили отдельную страницу, по заранее созданному шаблону. На странице риска, кроме обязательных названия и классификаторов, было подробное описание содержания, последствий, а также план действий со сроками и ответственными, и статус риска. Примерно так же были организованы открытые вопросы.
Специальная страница автоматически собирала список страниц с рисками, образуя таким образом реестр рисков.
Просматривая список можно перейти на соответствующую страницу, прочитать описание риска и посмотреть план действий по нему.
План действий может представлять из себя простой текст, задачу в Confluence или ссылку на задачу в JIRA.
Рассмотрим варианты, которые можно использовать, которые позволяют напоминать о действиях участникам и контролировать их исполнение.
Задача в Confluence — это отдельная сущность, которую можно добавить на страницу. Напоминание о задаче высвечивается для пользователя, когда он входит на портал, значком в правом верхнему углу. Кликнув по этому значку пользователь переходит к списку своих поручений. Когда задача выполнена, он ставит галочку, и статус задачи меняется за завершенный.
Однако так же точно можно снять галочку и задача опять становится не выполненной. Поэтому такая система выглядит не очень надежно и контроль за поручениями в этом случае слабый.
Второй вариант — использование для поручений задач в JIRA. Непосредственно со страницы проектного портала можно создать задачу в JIRA, назначить ответственного и установить срок исполнения. Для этого мы сделали специальный макрос, срабатывающий по кнопке Создать поручение.
В отличие от предыдущего варианта эта задача может быть настроена так, чтобы ее мог закрыть только ответственный, отличный от исполнителя, что дает хороший контроль ее выполнения.
Практика, которой мы придерживались, помогала нам сохранять все решения, которые мы принимали на совещаниях. В ходе каждого совещания мы вели протоколы непосредственно на портале проекта. В начале каждого совещания мы создавали новую страницу протокола на основании шаблона, и записывали основные моменты по ходу обсуждения. В конце формулировали решение и план действий.
Если кто-то после совещания хотел уточнить текст протокола, тот мог это сделать прямо на страничке портала, и было видно, кто и когда какие изменения внес. Протокол считался согласованным сразу после совещания, это экономило массу времени.
JIRA — Система для ведения списков, поручений, задач
JIRA создана как система регистрации и исполнения запросов на обслуживание. Однако она может быть использована для ведения любых реестров и управления любыми задачами.
В нашем проекта мы использовали JIRA для контроля исполнения поручений, ведения разработок и отслеживания задач по конвертации данных.
Ведение разработок с помощью JIRA подробно описано в статье Управление разработками. Здесь я расскажу о контроле поручений и интеграции с Confluence.
Для создания задачи JIRA из Confluence достаточно выделить текст, навести курсор на выделенный текст и нажать кнопку в контекстном меню, чтобы вызвать экран JIRA для создания задачи.
На странице протокола появится ссылка на задачу, а в задаче JIRA будет ссылка на страницу в Confluence.
Таким образом мы можем переходить между этими двумя системами, с одной стороны, чтобы уточнить состояние и историю исполнения поручения, а с другой — посмотреть контекст и причину возникновения задачи.
Интеграция между системами также помогала нам отслеживать списки открытых вопросов, связанными с разработками.
В конце проекта, когда остался список критичных разработок, которые необходимо было закрыть для завершения проекта, мы организовали его в виде таблицы на странице портала проекта, в одной из ячеек которой была ссылка на разработку в JIRA. Кроме номера задачи там отображается и текущий статус. Просматривая список мы можем видеть, какие задачи еще не закрыты, в каком состоянии они находятся, и при необходимости можем перейти к ней, чтобы увидеть всю историю и переписку по ней.
Работа с JIRA требует определенной квалификации и опыта. Здесь я описал некоторые варианты использования, однако на самом деле их гораздо больше. Прелесть в том, что можно начать с самых базовых вещей, и это уже будет работать, а затем развивать систему по мере приобретения опыта и понимания потребностей.
Кроме Confluence, в интеграции с JIRA, мы также использовали BitBucket, также продукт Atlassian — репозиторий разработок, позволяющий отслеживать версии кода. Для этих же целей на другом проекте использовали бесплатный SVN.
Множество плагинов позволяет расширять функциональность системы, в частности, для интеграции с MS Project или реализации диаграммы Гантта непосредственно в JIRA.
Большое количество вариантов использования может стать препятствием для тех, кто берется за использование этих инструментов в первый раз. В этом случае можно воспользоваться опытом других проектов, которых великое множество, либо начать с самого простого.
Организация проектного пространства с помощью JIRA и Confluence доказало свою эффективность и удобство. Ключевые преимущества — это удобство, надежность и широчайшие возможности для адаптации. На наших проектах такая системам стала стандартом де факто.
Настройка Jira под ваши нужды. Cовершенный флоу и идеальный тикет

Если вы работаете в IT-компании, то, скорее всего, ваши процессы построены вокруг известного продукта Atlassian — Jira. На рынке есть множество таск-трекеров для решения тех же задач, в том числе open-source-решения (Trac, Redmine, Bugzilla), но, пожалуй, именно Jira имеет сегодня самое широкое распространение.
Меня зовут Дмитрий Семенихин, я тимлид в компании Badoo. В небольшом цикле статей я расскажу, как именно мы используем Jira, как настраивали её под свои процессы, что хорошего «прикрутили» сверху и как тем самым превратили issue-трекер в единый центр коммуникаций по задаче и упростили себе жизнь. В этой статье вы увидите наш флоу изнутри, узнаете, как можно «докрутить» свою Jira, и прочтёте о дополнительных возможностях инструмента, о которых могли не знать.
Статья ориентирована прежде всего на тех, кто уже использует Jira, но, возможно, испытывает сложности с интеграцией её стандартных возможностей в существующие в компании процессы. Также статья может быть полезна компаниям, которые используют другие таск-трекеры, но столкнулись с некоторыми ограничениями и подумывают о смене решения. Статья построена не по принципу «проблема — решение», в ней я описываю сложившийся инструментарий и фичи, построенные нами вокруг Jira, а также технологии, которые мы использовали для их реализации.
Дополнительные возможности Jira
Чтобы последующий текст был более понятным, давайте разберёмся, какие инструменты предоставляет нам Jira для реализации нестандартных хотелок — тех, что выходят за рамки стандартного функционала Jira.
REST API
В общем случае вызов команды API — это HTTP-запрос к URL API с указанием метода (GET, PUT, POST and DELETE), команды и тела запроса. Тело запроса, а также ответ API — в JSON-формате. Пример запроса, который вернёт JSON-представление тикета:
С помощью API вы можете, используя скрипты на любом языке программирования:
Мы написали собственный высокоуровневый Jira API-клиент на PHP, который реализует все необходимые нам команды. Вот пример команд для работы с комментариями:
Webhooks
С помощью webhook можно настроить вызов внешней callback-функции на вашем хосте на различные события в Jira. При этом можно настроить сколько угодно таких правил таким образом, что различные URL будут «дёргаться» для разных событий и для тикетов, которые соответствуют указанному в webhook фильтру. Интерфейс настройки webhooks доступен администратору Jira.
В результате можно создавать правила вроде этого:
Name: “SRV — New Feature created/updated”
URL: www.myremoteapp.com/webhookreceiver
Scope: Project = SRV AND type in (‘New Feature’)
Events: Issue Updated, Issue Created
В данном примере указанный URL будет вызываться для событий создания и изменения тикетов, соответствующих фильтру Scope. При этом в теле запроса будет содержаться вся необходимая информация о том, что именно изменилось и какое событие произошло.
Тут важно понимать, что Jira не гарантирует, что ваше событие будет доставлено. Если внешний URL не ответил или ответил с ошибкой, это нигде видно не будет (кроме логов, пожалуй). Поэтому обработчик событий webhook должен быть максимально надёжным. Например, события можно складывать в очередь и пытаться обработать до тех пор, пока это не закончится успехом. Это поможет решить проблемы с временно недоступными сервисами, например, какой-либо внешней базой данных, необходимой для правильной обработки события.
Подробная документация о webhooks представлена по ссылке.
ScriptRunner
Это плагин к Jira, очень мощный инструмент, который позволяет кастомизировать в Jira очень многое (в том числе он способен заменить собой webhooks). Для пользования этим плагином требуется знание Groovy. Основное преимущество инструмента для нас состоит в том, что можно встраивать во флоу кастомную логику в режиме онлайн. Код вашего скрипта будет исполняться сразу в среде Jira в ответ на определённое действие. Например, можно сделать в интерфейсе тикета свою кнопку, клик по которой будет создавать связанные с текущей задачей тикеты или запускать юнит-тесты для данной задачи. И если вдруг что-то пойдёт не так, вы как пользователь сразу об этом узнаете.
Желающие могут ознакомиться с документацией.
Флоу: что скрыто под капотом
А теперь о том, как мы применяем дополнительные возможности Jira в наших проектах. Рассмотрим это в контексте прохождения нашего типичного тикета по флоу от создания до закрытия. Заодно и про сам флоу расскажу.
Open/Backlog
Итак, сначала тикет попадает в беклог новых тикетов со статусом Open. Далее лид компонента, увидев новый тикет на своём дашборде, принимает решение: назначить тикет прямо сейчас разработчику либо отправить его в беклог известных тикетов (статус Backlog), чтобы назначить его позже, когда появится свободный разработчик и более приоритетные тикеты будут закрыты. Это может показаться странным, так как кажется логичным делать наоборот: создавать тикеты в статусе Backlog, а потом переводить в статус Open. Но у нас прижилась именно эта схема. Она позволяет легко настроить фильтры, чтобы сократить время принятия решения по новым тикетам. Пример JQL-фильтра, который показывает новые задачи лиду:
Project = SRV AND assignee is EMPTY AND status in (Open)
In Progress
Надо отметить, что у нас работа над каждой задачей ведётся в отдельной Git-ветке. Насчёт этого у нас есть соглашение, что имя ветки в начале должно содержать номер тикета. Например, SRV-123_new_super_feature. Также комментари к каждому коммиту в ветку должны содержать номер тикета в формате [SRV-123]:
Эти требования контролируются Git-хуками. Например, вот содержимое prepare-commit-msg, который подготавливает комментарий к коммиту, получая номер тикета из имени текущей ветки:
Если коммит с «неправильным» комментарием попытаться запушить, такой пуш будет отклонён. Также отклонена будет попытка запушить ветку без номера тикета в начале.
Когда тикет попадает на разработчика, первым делом он декомпозируется. Результатом декомпозиции является представление разработчика о способах решения задачи и о том, сколько времени займёт решение. После того как все основные детали выяснены, тикет переводится в статус In Progress, а разработчик начинает писать код.
У нас принято выставлять задаче due date в момент, когда она переводится в статус In Progress. Если же разработчик этого не сделал, ему придёт напоминание в корпоративный мессенджер HipChat. Специальный скрипт раз в два часа:
Что ещё?
Ещё с помощью API и webhooks Jira мы делаем такие вещи:
Итоги
Jira — прекрасный инструмент, который в стандартной поставке позволяет решать большинство проблем, связанных с организацией ведения проектов. Но, как известно, в любом бизнесе есть свои нюансы. И для адаптации Jira к особенностям ваших процессов этот продукт обладает дополнительными возможностями, которые в умелых руках позволят вам решить практически любую проблему.
В следующей статье я планирую поделиться нашим опытом по настройке дашбордов — лидских и девелоперских. Также расскажу про настройку уведомлений в Jira и поделюсь секретами о том, как мы организуем синхронизацию работы разных команд на базе Jira. Надеюсь, что-то из нашего опыта пригодится и вам.