Что такое бит, байт килобайт, мегабайт, гигабайт, терабайт и как они связаны между собой?
Приветствую, на связи Алексей! Все, кто так или иначе работает или с компьютером, или с планшетом, сталкивается с такими понятиями, как «бит», «байт», «мегабайт» и пр.
А не сталкиваться с ними невозможно, поскольку это единицы измерения информации, которую мы получаем в интернете, копируем на флешки или переносим на диски. Представляя себе этот самый объем файлов, мы сможем выбирать необходимый носитель, чтобы хватило места для копируемых файлов.
В противном случае вы, просто на просто, не сможете сохранить информацию. Любой файл имеет свой определенный объем или, как еще говорят, «вес». Таким образом, байт, мегабайт, гигабайт, терабайт, петабайт и пр. определяют емкостное количество любого цифрового хранилища. У этих единиц есть родственные: мегабит, мегабайт и гигабит и многие их путают. Но, в отличие от битов, байтов, мегабит и мегабайт применимы при изменении скорости передачи данных, т. е. интернета.

Итак, давайте разберемся, что это за единицы объема информации, что они означают и как переводятся одна в другую.
Единицы измерения информации, история возникновения
Для чего нужны единицы измерения информации? Ведь это такое эфемерное понятие… До этого уже измеряли практически все, что можно измерить. Но вот как быть с информацией? Казалось бы, как можно измерить информацию заключенную, например, на листочке бумаги или же выраженную звуком. Однако можно. Для нее была придумана такая минимальная единица, как бит. И ввел ее в 1948 году Клод Элвуд Шеннон.

В своей статье «Математическая теория связи» он впервые ввел такое слово, как «bit», которым и обозначил наименьшую единицу количества информации. Правда слово это он позаимствовал у Джона Тьюки, который использовал это слово, как сокращенное от «binary digit». Родился Клод Шеннон в 1916 году в городе Гэйлорде штата Мичиган. С детства он увлекался техникой и математикой.
Это казалось бы рядовое событие явилось одним из тех кирпичиков, на котором стоит фундамент того, что мы называем «информационные технологии». С появлением единиц измерения информации, человечество постепенно осознало, что все знания на земле можно перевести в цифровые значения; в этом же виде информацию можно передать на расстояние хранить и обрабатывать.
В 1940 году Клод Шеннон защитил диссертацию, в которой доказал, что работу переключателей и реле в электрических схемах можно представить методами алгебры. Эта работа, впоследствии, стала основополагающей для развития такого раздела кибернетики, как теория информации. Таким образом, это понятие исчисления количества информации прижилось и сейчас имеет очень широкое применение.
Наравне с битом, существует и еще одна единица количества информации – байт.
Что такое бит и байт?
Что же такое эти самые бит и бай?. Как говорилось ранее, бит – это сокращенное слово от «binary digit», что означает двоичное или бинарное число. Таким образом бит воспринимает два числа – 0 или 1.
Но восемь бит представляют собой уже символ и называется это – байт. Таких последовательностей, состоящих из восьми бит 256. Этого вполне достаточно, что бы представить любой символ.

Таким образом, каждый символ равен восьми битам или одному байту. Термин «байт» был введен гораздо позже термина «бит». В 1964 году его ввел Вернер Бухгольц, который работал в IBM.
Название этого термина произошло от названия BInary digiT Eight, что означает двоичное число восемь. Что бы не путать новое название с уже имеющимся BIT (BInary digiT), буква I была заменена на букву Y. В результате и появилось новое название BYTE (байт).
Как и другие системы исчисления, веса, объема, расстояния, единицы измерения информации имеют несколько вариантов, обозначающихся приставками: килобайт, мегабайт, терабайт и пр.
Так же как, скажем граммы переводятся в килограммы и наоборот, единицы информации тоже могут переходить одна в другую. Используя их, мы можем четко определять каков у нас объем необходимой информации, и какое хранилище хорошо подойдет для ее переноса или хранения.
Способы перевода битов в байты
Самой маленькой единицей именно хранения информации, считается мегабайт, которое обозначается, как МБ. Например, одна песня занимает в среднем от 3 до 5 Мб. Популярные некогда CD-диски были объемом в 650 Мб. Впрочем, и самая «весомая» флешка была в 250 Мб. Сейчас эти объемы уже никого не устроят. В переводе мер, 1 мегабайт равен 1024 Килобайтам.
Сейчас оптимальной единицей хранения информации считается гигабайт – Гб. Посмотрите на свои накопители информации, они все измеряются в гигабайтах. Пришедший на смену CD-диску DVD-диск имеет объем уже в 4,7 ГБ. Жесткие диски компьютеров измеряются уже минимум в 500 Гб.
Но развитие технических характеристик носителей не стоит на месте и сейчас уже в ходу новые объемы, такие как «терабайты». При покупке нового компьютера жесткий диск в ГБ нас уже не устраивает, подавай в ТБ. На сегодня, практически вся информация, которая «гуляет» по сети интернет уже измеряется в терабайтах. Все эти единицы легко переводятся друг в друга.

Но и это еще не предел. Существуют такие единицы, как Петабайты Пб. В одном петабайте находится уже 1024 Тб, в одном Тб – 1024 ГБ, в одном Гб – 1024 Мб, в одном Мб – 1024 Кб. Можно подсчитать, сколько таких Кб будет содержаться в одном Пб.
Например, в стандартный лист А4 формата содержится около 100 килобайт печатного текста. В одном же Пб содержится уже пятьсот миллиардов страниц такого текста. И еще одна, самая большая единица хранения информации – Эксабайт Эб. В одном Эб содержится уже 1024 петабайтов. Это достаточно огромное хранилище, которое пока вряд ли необходимо рядовому пользователю.
Например, в 1 ЭБ можно «уместить» одиннадцать миллионов видео в стандарте высокого разрешения. Кто-то может облизнется от такого объема. Но, не отчаивайтесь, не далеко то время, когда наши компьютеры будут снабжены такими жесткими дисками.
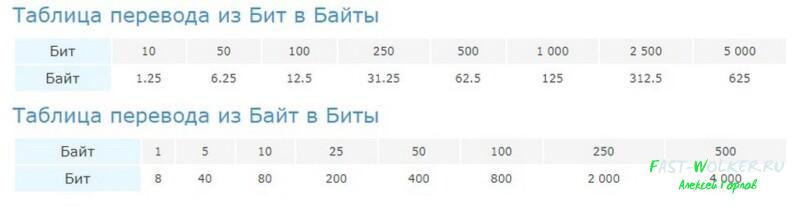
Кстати, если говорить о звуках, то примерно подсчитано, что все слова, произнесенные людьми можно уместить в 5Эб. Что бы самостоятельно определить сколько в байтах битов, в гигабайтах килобайт и т.д., можно воспользоваться такой схемой.
Если вы не хотите заморачиваться математическими подсчетами, можно или в табличном редакторе MS Excel создать форму для пересчета, или же воспользоваться онлайн конвертерами.
Как видите, ничего сложного в понятии количества информации нет. Но представлять себе это необходимо, поскольку мы всегда храним нужную информацию, переносим ее с одного места на другое. От этого зависит выбор хранилища для нашей информации. Успехов!
О битах, байтах и скорости интернет соединения

Для начала попробуем разобраться, что же такое биты и байты. Бит это самая наименьшая единица измерения количества информации. Наравне с битом активно используется байт. Байт равен 8 бит. Попробуем изобразить это наглядно на следующей диаграмме.

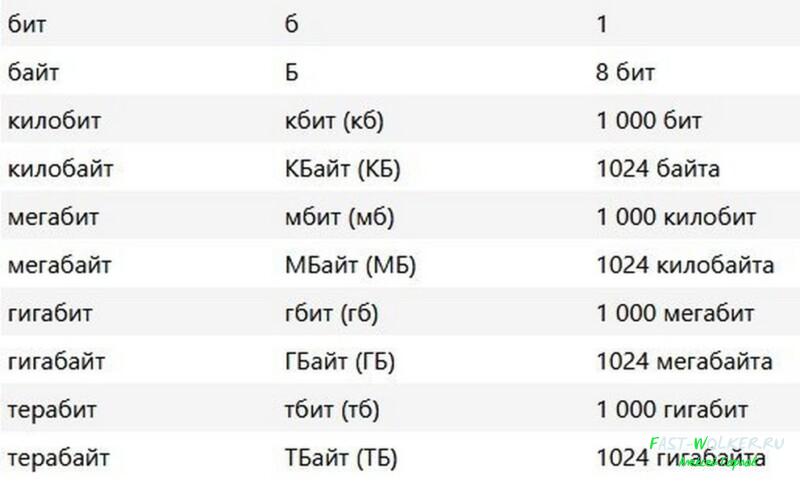
Думаю, с этим все понятно и не имеет смысла останавливаться подробнее. Так как бит и байт это очень маленькие величины, то в основном они используются с приставками кило, мега и гига. Наверняка вы слышали о них еще со школьной программы. Общепринятые единицы и их сокращения мы соединили в таблицу.
| Название | Аббревиатура английская | Аббревиатура русская | Значение |
|---|---|---|---|
| бит | bit (b) | б | 0 или 1 |
| байт | Byte (B) | Б | 8 бит |
| килобит | kbit (kb) | кбит (кб) | 1000 бит |
| килобайт | KByte (KB) | КБайт (KБ) | 1024 байта |
| мегабит | mbit (mb) | мбит (мб) | 1000 килобит |
| мегабайт | MByte (MB) | МБайт (МБ) | 1024 килобайта |
| гигабит | gbit (gb) | гбит (гб) | 1000 мегабит |
| гигабайт | GByte (GB) | ГБайт (ГБ) | 1024 мегабайта |
Теперь попробуем определиться с величинами измерения скорости интернет соединения.
Говоря понятным языком, скорость подключения это количество получаемой или отправляемой вашим компьютером информации в единицу времени. В качестве единицы времени в данном случае принято считать секунду а в качестве количества информации кило или мегабит.
Таким образом, если ваша скорость 128 Kbps это означает, что ваше соединение имеет пропускную способность 128 килобит в секунду или же 16 килобайт в секунду.
Много это или мало судить вам. Для того чтобы более материально почувствовать вашу скорость рекомендую воспользоваться нашими тестами. Определить время, необходимое для закачки файла, определенного вами размера, при вашей скорости подключения. Также вы можете посмотреть, файл какого объема вы сможете скачать за определенный вами период времени при вашей скорости подключения.
Используя наши тесты необходимо помнить и учитывать, что наш сервер, на котором собственно и расположены все эти тесты находится от вашего компьютера достаточно далеко и соответственно на результатах может сказываться как загруженность нашего сервера (на нашем сайте в часы пик одновременно производят замер скорости соединения более 1000 человек), так и загруженность интернет линий.
Если бы наш сервер стоял за одним столом с вашим компьютером и они были бы подключены друг к другу одним проводом, тогда можно было бы вести речь о наиболее точных результатах. В нашем же случае, как показывает практика, подключение вашего компьютера к нашему серверу для тестирования происходит в среднем через 10 других серверов.
Единицы измерения информации в компьютерах.
Говоря проще, скорость подключения это количество получаемой или отправляемой вашим компьютером информации в единицу времени.
Единицы измерения информации:

Бит (bit) – базовая единица измерения информации, может содержать только одну двоичную цифру. Бит может принимать только два значения: «0» или «1».
Байт (byte) – также единица количества информации, один байт равен восьми битам

Приставки К, М, Г, Т («кило-», «киби-» и т. д.)
Чтобы измерять большие объемы данных, используют кратные приставки. Привычная же нам приставка «кило-» означает умножение на 1000 (10х3 ), но в двоичной системе счисления используют два в десятой степени (2х10 ).
Двоичная система счисления
Для обозначения величины 2х10 =1024 байт, ввели двоичную приставку «К» (именно прописная буква «К»), но в разговорной речи единицу «К» стали называть «кило», что не совсем одно и то же. Чтобы не путаться ввели названия приставкам:
Т. е. второй слог изменили с привычного на «би», «бинарный».
Но от этого легче не стало, путаница не исчезла и многие расшифровывали «К» и «М» привычными «кило» и «мега».
Короче в итоге, чтобы окончательно убрать несоответствие, изменили не только названия,

Но как Вы понимаете от этого опять же легче не стало.
В народе говорят «кило», в программах ОС Windows пишут«К», в Linux обозначают «Ки»,
а производители жестких и оптических дисков пишут«К», а имеют в виду « Ки » и т. д.
В итоге на сегодняшний день имеются три варианта использования двоичных приставок.

Двоичные приставки в ОС Windows и производителей ОЗУ
1Кбайт (КБ или KB или Kbyte) = 1024байт
1Мбайт (МБ или MB или Mbyte) =1024Кбайт
1Гбайт (ГБ или MB или Gbyte) =1024Мбайт
1Тбайт (ТБ или TB или Tbyte) =1024Гбайт

В свойствах файлов почти все программы, да и сама операционная система Windows использует приставку в виде прописной буквы «К», «М», «Г» и т. д.
Производители оперативной памяти используют тот же принцип.
Двоичные приставки в ОС Windows и у производителей ОЗУ 1 Кбайт (КБ или KB или
Использование десятичных приставок
Если используется приставка «кило», «мега», «гига» и т. д., то имеются в виду следующие соотношения:
Десятичный приставки используют производители накопителей

1 килобайт (кБ или kB или kbyte) =1000 байт
1 мегабайт (МБ или MB или Mbyte)=1000килобайт=1 000 000байт
1гигабайт (ГБ или GB или Gbyte) =1000мегабайт=1 000 000Кбайт=1 000 000 000байт
1терабайт (ТБ или TB или Tbyte) =1000гигабайт=1 000 000Мегабайт=1 000 000 000Кбайт=1 000 000 000 000байт
Многих начинающих юзеров вводит в ступор после установки ОС, что диск обьемом 1000гб, отображается, как 931гб.
Как Windows видит два жестких диска 1ТБ и 500ГБ
Производители считают, что в нем 1 000 000 000 килобайт, а ОС Windows делит на 1024 и получает 976 562 500 Кбайт ( кибибайт) или 931 Гбайт (гибибайт ).
Жесткий диск 500 ГБ отображается как 465.76 ГБ, а винчестер объемом 1000 ГБ
содержит всего 931.51 гигабайт, т. е .70 гигов никуда не делись, просто гиг и байт на жестком диске меньше, чем гиг а байт.
1КБ=1 кибибайт= 1024байт
Теперь Вы знаете сколько байт в килобайте, а сколько в кибибайте
(бит в килобите и в кибибите)
Блог Алексея Лебедева
То, что не влезает в твиттер
Один бит – сколько это?
Все просто, один бит – это количество информации, передаваемое одним бинарным сообщением, то есть одним сообщением из двух возможных. Например, ответ да/нет, 0/1 или влево/вправо.
Но не на столько просто. Важно, чтобы соблюдались два условия: третий варианта ответа невозможен и у вас до этого не было никакой информации о заданном вопросе. То есть, если вы спрашиваете у вашей новой знакомой, замужем ли она, то ее ответ почти никогда не будет содержать ровно один бит инормации. И не только потому, что кроме ответов да/нет она может ответить “не ваше дело” или “раведена”, но еще и потому что вы заранее можете оценить вероятность того, что она замужем: по ее возрасту, по поведению или по кольцу на пальце.
Хорошо, дальше все легко, два бита – это в два раза больше, чем один. Но что именно означает “в два раза больше”?
Во-первых, для простоты давайте абстрагируемся от формы ответа и будем считать, что один из двух возможных ответов всегда 0, а другой – 1: нет – 0, да – 1 или влево – 0, вправо – 1 и т. д.
Итак, двумя битами можно, например, представить информацию о маршруте, на котором есть две развикли, то есть всего четыре маршрута: дважды влево, влево-вправо, вправо-влево и дважды вправо. Нетрудно посчитать, что если маршрутов восемь, то для выбора одного из них, нужно три бита. А в общем случае, для кодирования одного из N состояний (о которых у нас нет предварительной информации), требуется log2 N бит.
На этом все. Теперь вы знаете все о том, как измеряется количество информации.
На самом деле нет. Жизнь была бы слишком простой.
Где-то в этих рассуждениях есть фундаментальная ошибка. В самом деле, посмотрите на следующие два сообщение, где каждый бит закодирован цифрами 0 и 1:
Забудьте все, что я вам сказал до этого и, основываясь только на интуиции, ответьте на вопрос, в каком сообщении больше информации.
М-да. Что же делать? Не то, чтобы предыдущее определение было полностью неверным, но оно не соответствует нашему интуитивному пониманию информации.
Интуитивно, в первом сообщении больше информации, потому что оно выглядит более случайным. А еще важнее то, что если вы захотите продиктовать обе последовательности по телефону, то в первом случае трудно придумать что-то более оптимальное, чем просто проговаривание цифр одна за другой, в то время как для передачи второго, можно просто сказать “восемнадцать раз 01”.
Может быть правильно было посчитать сколько информации в сообщении “восемнадцать раз” и добавить два? Это можно попытаться сделать: записать восемнадать в двоичной системе – 10010, а потом закодировать понятие “раз”: запишем 0, если следующие цифры – непосредственно само сообщение, и 1, если используется формулировка “N раз M”, где M – сообщение, которое предполагается повторить N раз. Саму формулировку “N раз M” запишем так: сначала N в двоичной системе, причем каждую цифру запишем дважды (00111100 вместо 0110), затем цифры 01, а затем сообщение M. Цифры числа N будем дублировать, чтобы было понятно, когда заканчивается N и начинается M, 01 будет играть роль разделителя, ведь если его пропутить, то если M начинается с двух одинаковых цифр, то будет непонятно, это окончание N или начало M.
Этот нехитрый трюк позволяет записать исходное сообщение из 18 пар 01 строкой 111000011000101, а это всего 15 бит. Правда сообщения из цифр, в которых нет повторяющихся последовательностей, придется записывать по-прежнему полностью, да еще и в придачу приписывать ко всем 0, чтобы отличить их от закодированных.
Зачем все это? Ах да, мы хотели оценить количество информации в сообщении таким образом, чтобы чтобы это больше соответствовало нашему интуитивному понятию информации. Получается в нашем исходном первом сообщении 19 бит информации, а во втором – 15. Что ж, это уже лучше. Немного смущает тот факт, что в первом сообщении мы теперь считаем один “лишний” бит, но зато наша оценка больше соответствует нашей интуиции: во втором сообщении информации меньше.
Ну как, удалось ли мне вас убедить, то такая оценка лучше, чем простой подсчет цифр?
Но нельзя сказать, что идея совсем безнадежна. Не будем ее отбрасывать, а вместо этого попробуем ее немного улучшить.
Во-первых, смущает то, что ко всем сообщениям без повторений мы приписывам 0, а во вторых даже если повторения есть, иногда закодировав сообщение вышеописанным способом, цифр становится больше а не меньше.
Но если подумать, первый недостаток не так уж и важен при оценке очень длинных сообщений, а от второго недостатка можно избавиться, если для таких сообщений не использовать кодирование, а записывать их как есть.
Более фундаментальную проблему мы увидим, если попытаемся оценивать количество инофрмации в таких сообщениях, где нет повторений, а вместо этого угадывается другая регулярность. Например, интуиция подсказывае, что во втором сообщении меньше информации:
Потому что, опять же, если представить, что мы заходим его продиктовать по телефону, скорее всего мы скажем что-то вроде “восемь единиц, разделенных нулями, причем количество нулей увеличивается каждый раз на один, то есть один, ноль, один, два нуля, один, три нуля и т. д.”
Эта формулировка кажется длинной и запутанной, и возможно на практике некоторые предпочтут проговорить все цифры как есть, но я готов поспорить, что если бы эта последовательность состояла из миллиона цифр, то вы бы поменяли свое мнение.
Тогда можно действовать по старому плану: придумать как закодировать нулями и единицами фразы типа “N единиц, разделенных нулями. ” и т. д.
Ну а теперь, я бы хотел спросить как на счет строки 1000000000000000000000000001, но боюсь, что вы начнете в меня кидать тухлыми помидорами, ведь примеров строк с различными регуляностями бесконечно много. И даже если согласиться, что оценка, использующая то или иное кодирование, имеет некоторый смысл, она никогда не будет идиальной, потому что всегда найдется регулярность, для которой мы еще не придумали способ кодирования.
А кроме того, как быть, если одну и ту же строку можно закодировать несколькими способами?
На этот вопрос есть простой ответ, который предложил Рей Соломонофф в 1960 году.
Вместо придумывания разных способов кодирования регулярных (в каком бы то ни было смысле) строк, мы воспользуемся какой-нибудь универсальной алогритмической моделью, например универсальной машиной Тьюринга. То есть, для оценки количества информации в строке, мы выпишем все возможные описания машин Тьюринга вместе с исходными состояниями ленты такие, что при после окончании работы машины, на ленте будет записана наша исходная строка. Из всех этих описаний мы выберем самое короткое. Именно его длинну мы и возьмем за меру количества информации.
Нет? Давайте по-порядку. Универсальная машина Тьюрига – это открытие, которое сделал Тьюринг в 1936 году. Оно описано в статье под названием “О вычислимых числах с приложением к проблеме разрешимости” на 36 страницах.
В статье описывается построение машины Тьюринга, которая является универсальной в том смысле, что она выполняет не заранее заданный алгоритм, а алгоритм, который записан на ленте в качестве входных данных. Причем этот алгоритм записывается в виде описания машины Тьюрига. То есть показывается по крайней мере теоретическая возможность создания машины, которая может выполнять любой алгоритм, неизвестный заранее в момент конструирования машины.
Сегодня этим вряд ли кого-то удивишь. Все современные, и не очень, компьютеры обладают этим свойством. Вы покупаете компьютер не под конкретную задачу, а универсальный. Какую задачу он будет решать, зависит от того, какую программу вы на нем запустите. Но в 1936 году это было фундаментальное открытие. До Тьюрига все создаваемые машины проектировались для выполнения одного конеретного алгоритма.
Если вы заинтересовались, я рекомендую прочитать книгу Пецольда “Annotated Turing”, в которой подробно, абзац за абзацем, разбирается работа Тюринга 1936 года. Ну а самые стойкие могут прочитать оригинальную статью.
В любом случае, какое отношение это имеет к нашей оценке информации? Универсальная машина Тьюрига – это, по просту говоря, компьютер с бесконечной памятью. Он считывает программу, записанную в памяти (в МТ – на ленте), и выполняет ее. Входные данные берутся тоже из памяти (записаны рядом на ленте).
Так вот, для оценки количества информации в сообщении, мы выпишем все возможные программы и их входные данные, такие, что результатом работы этих программ является наше сообщение. Самую короткую их этих программ (и ее иходные данные) мы и будем считать самым лучшим представлением сообщения, а ее длинну, опять включая входные данные, – количеством информации в нем.
Естественно, перебрать все возможные программы, не так-то просто. На самом деле, дела обстоят еще хуже – это сделать в общем случае невозможно. Если вам интересен этот вопрос, я рекомендую книгу Майкла Сипсера, в которой очень понятным языком описываются техники доказательства теорем о вычислительной неразрешимости различных проблем. Но для наших целей это не так уж и важно.
В самом деле, не всегда важно знать точное количество информации в сообщении, если есть возможность ее оценивать прибилизительно или сравнивать различные сообщения “по информативности” между собой.
Но если вы думаете, что такое определение имеет слишком ограниченную сферу применения, вы совершенно правы. Настолько правы, что никто на практике им не пользуется, а вместо этого по-старинке называет количеством информации число нулей и единиц в сообщении, каким бы простым и регулярным оно ни было.
А то, что я описал, называют дискриптивной сложностью, или просто сложностью. В некоторых источниках ее еще называют сложностью Колмогорова-Хайтина, а также алгоритмической энтропией, а также другими очень умными, но мало о чем говорящими, словами.